

 English
English文献解读|Cell(45.5):53,026 名成年人健康和疾病血浆蛋白质组图谱
✦ +
+
论文ID
原名:Atlas of the plasma proteome in health and disease in 53,026 adults
译名:53,026 名成年人健康和疾病血浆蛋白质组图谱
期刊:Cell
影响因子:45.5
发表时间:2024.11.22
DOI号:10.1016/j.cell.2024.10.045
背 景
随着全球人口的快速增长和老龄化,增进健康、减轻疾病负担的需求与日俱增。疾病预防和治疗的挑战包括缺乏可靠的个体化风险预测模型以及现有治疗方法的疗效和不良反应的差异,这更凸显了精准医疗的重要性。目前,精准医疗的实施主要集中于确定人类疾病的基因组基础,并已显示出初步成效。然而,基因转录和翻译中复杂且不确定的调控过程阻碍了因果基因的推断,从而限制了基于基因组到表型组关联的机制理解和药物开发。蛋白质是疾病遗传和环境风险的最终生物效应物,直接反映人体的生物学过程和病理生理变化。阐明蛋白质与疾病的关系有望表征不同健康状态和疾病状况的生物学特征,从而提高精准医疗的便利性和可行性。
实验设计
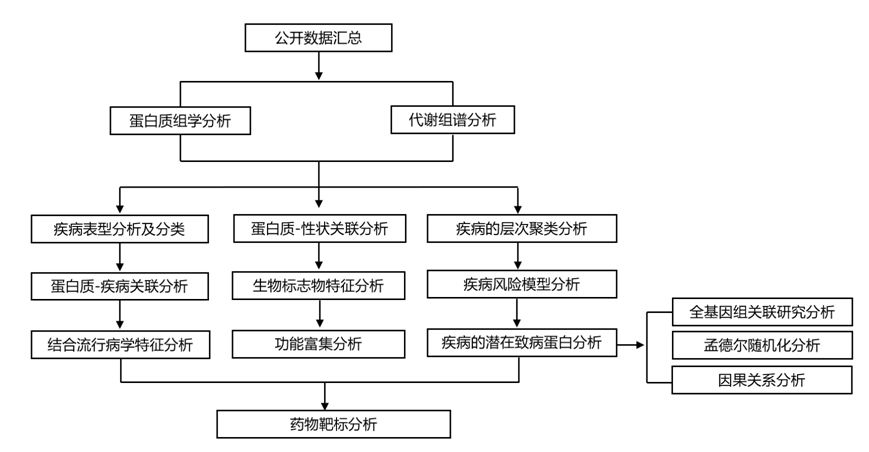
结 果
01

蛋白质-疾病关联图谱
研究团队纳入了 53,026 名参与者,平均年龄为 56.8 岁,其中 53.9% 为女性,93.7% 为白种人。后续调查中纳入了 2,920 种符合质量控制标准的蛋白质。研究包括两大类表型,包括疾病和健康相关性状(图1A)。流行疾病终点是二元结果,在采血前和采血发生了 100 多个事件。总共纳入了 406 个流行疾病终点、660 个新发疾病终点和 986 个健康相关性状。流行疾病分为 14 个章节,其中消化系统疾病占比最大(17.2%)(图S2A)。每章节平均流行疾病病例数在 286 至 865 之间,其中循环系统疾病排名最高(图S2B)。新发疾病分为 13 个章节(图S2A),每章节平均新发疾病病例数在 483 至 1,508 之间,其中循环系统疾病排名最高(图S2B)。根据英国生物银行 (UKB) 路径将性状分为 11 个章节,其中核磁共振 (NMR) 波谱衍生的代谢组学谱占比最大,达 25.5%(图S2C)。各章节的特征平均样本量从 17,880 到 49,267 不等(图S2D)。
他们首先分别使用逻辑回归和 Cox 比例风险回归模型来分析 2,920 种蛋白质的循环水平与 406 种流行疾病和 660 种发病疾病之间的关系(图1A),确定了 60,942 个蛋白质-流行疾病对,它们显著相关(图 1 B)。此外,观察到 107,158 个显著的蛋白质-发病疾病关联(图 1 C)。正如预期的那样,已确定的关联包括与心脏原因死亡相关的 NTproBNP 和与糖尿病相关的 GDF15,是最重要的蛋白质流行疾病关联。WFDC2 与流感和肺炎等呼吸道疾病的风险有关,GDF15 与某些传染病和血液系统疾病有关,包括隐性脓毒症和贫血,这验证了先前的研究并证实了本研究方法的有效性(图 1 D)。值得注意的是,这些结果还揭示了以前从未报道过的蛋白质-疾病关联。最主要的关联主要发现于慢性肾病等新发泌尿生殖系统疾病中,包含先前报道的蛋白质生物标志物和未报道的高风险比 (HR) 的蛋白质生物标志物,包括 NBL1、COLEC12等。他们发现 1,977 个关联对流行病学和新发疾病均具有保护作用。在这些蛋白质中,EGFR 表现出最广泛和最显著的保护作用,影响 90 种疾病。最大的保护作用是对高血压肾病,支持 EGFR 信号在肾脏损伤中的关键作用。
然后,他们比较了流行病学和新发疾病之间的蛋白质排名和关联方向。在两项分析中同时观察到了大多数蛋白质-疾病关联(图 1 E)。根据蛋白质的p值对蛋白质进行排序,并计算每种蛋白质在其中排名第一的疾病数量。在排名第一数量最多的前 10 种蛋白质中,有 6 种在流行病学和新发疾病之间是相同的(GDF15、WFDC2、NTproBNP、CHGA、COL9A1 和 IGFBP4),这表明重要的蛋白质在疾病发作前后都会发生变化。此外,大多数蛋白质-疾病关联在流行病学和新发疾病之间表现出一致的影响,而 27 种蛋白质对流行病学和新发疾病表现出不同的影响(图 1 F)。例如,患有流行性 2 型糖尿病 (T2D) 的患者显示出较高的 DSG2、ART3 和 KLB 水平,而将这些蛋白质确定为发生 T2D 风险的保护因素。例如,参与细胞粘附和信号传导的 DSG2 最初可能保护胰岛细胞并有助于胰岛素分泌,但随着 T2D 进展其水平升高可能表明对胰岛素抵抗的补偿反应。因此,蛋白质普遍性和蛋白质发病率疾病的趋同关联可能强调其在疾病阶段的重要作用,而不同的关联则为蛋白质在疾病发病机制中的功能提供了额外的见解。
在敏感性分析中,当限制对照并进一步调整每个患病和发病终点的合并症状态时,80.5% 的蛋白质患病疾病和 74.9% 的蛋白质发病疾病关联仍然显著。他们还发现了性别特异性关联,在蛋白质发病率和蛋白质流行性疾病关联中分别发现了 37,979 和 22,911 个(图 1 G)。大多数关联在亚组中保持一致的方向,只有 18 个关联在亚组中表现出不同的效应方向(图 1 H)。
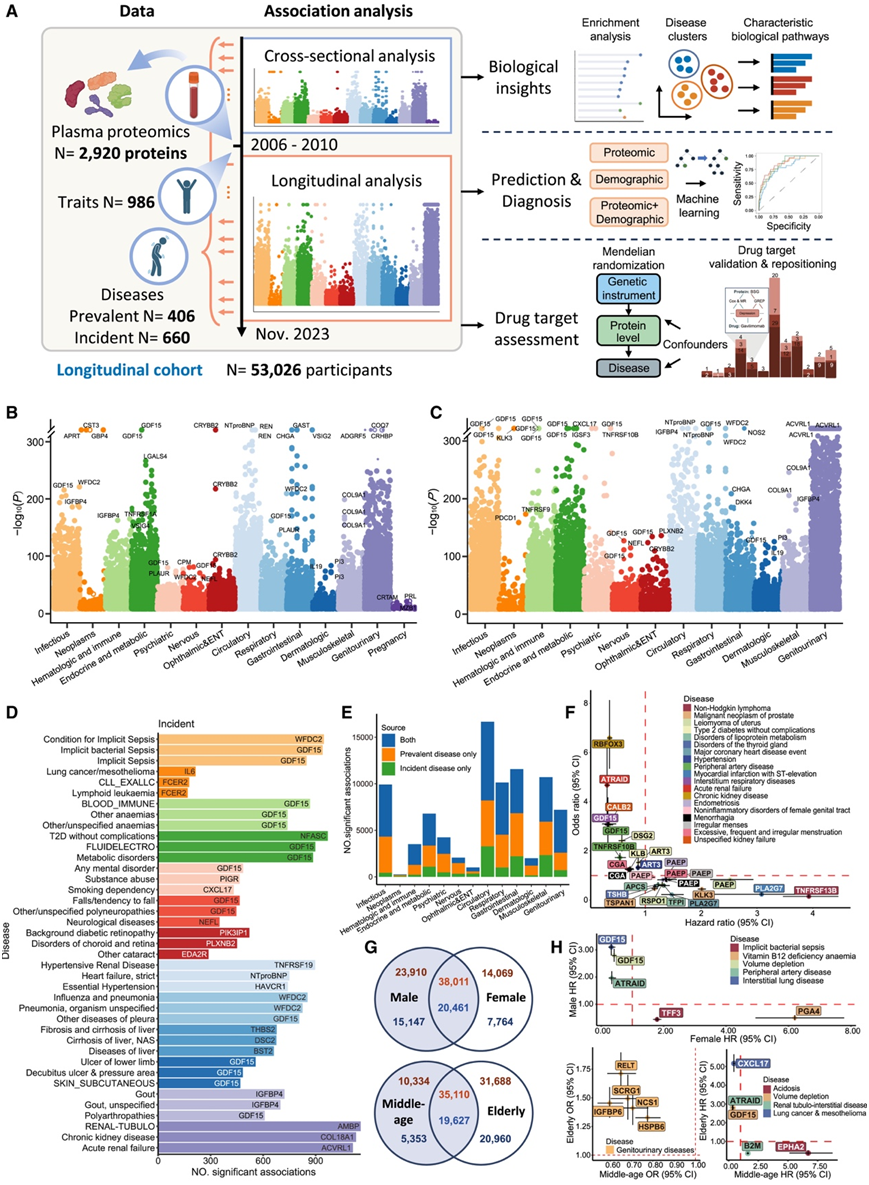
图1. 蛋白质-疾病关联分析结果汇总。
(A) 实验分析流程示意图。(B-C) (B) 逻辑回归和Cox 回归揭示的蛋白质-疾病关联。(D) 各疾病类型中具有最多显著关联的前三种发病疾病。(E) 流行疾病和新发疾病中显著关联数量的比较。(F) 与流行疾病和偶发疾病相关的蛋白质-疾病对方向不一致。(G) 性别(上)和年龄(下)亚组分析中显著关联数比较。(H) 性别和年龄亚组分析中方向不一致的蛋白质-疾病对。
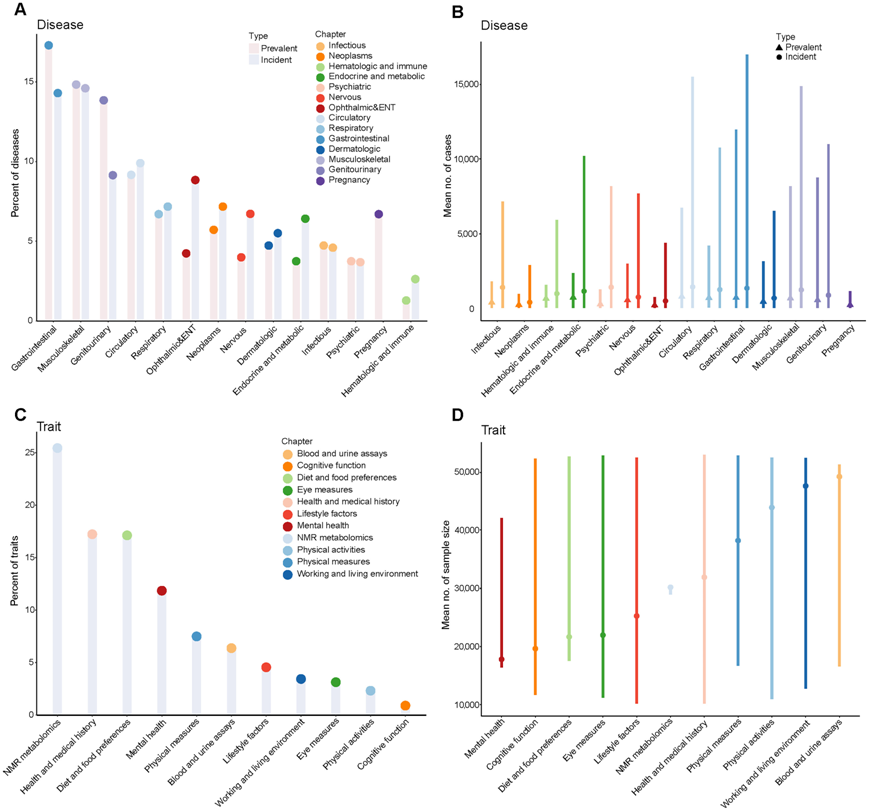
图S2. 表型的分布和样本大小。
(A) 本研究评估的流行疾病和发病疾病的百分比。(B) 按 ICD-10 章节分层的每种流行疾病和发病疾病的平均病例数。(C) 研究中评估的健康相关性状的百分比按 UKB 章节进行分类。(D) 按章节分层的每个特征的平均病例数。
02
蛋白质-性状关联图谱
接下来,他们确定了 554,488 个显著的蛋白质-性状关联,涉及 2,707 种蛋白质和 782 种性状(图 2 A)。蛋白质-性状关联分析的结果可能进一步支持已确定的蛋白质-疾病关联。例如,GDF15 和 CDCP1 与认知功能性状表现出最显著的关联。值得注意的是,GDF15和 CDCP1都是反应时间(reaction time)的风险蛋白,这为蛋白质-疾病关联分析中观察到的它们与神经精神疾病呈正相关的额外证据提供了证据。在调整更多协变量的敏感性分析中,99.3% 的最初确定的关联仍然显著。
在亚组分析中,超过 70% 的蛋白质-性状关联仍然显著。与认知功能和心理健康相关性状的蛋白质关联表现出更高的亚组特异性(图 2 B-C)。不同亚组之间共享关联的方向大致一致,但 235 种蛋白质按性别显示不同的效应方向,164 种蛋白质按年龄显示不同的效应方向。例如,OXT 是一种参与社会行为和健康的神经肽,29对女性的睾酮水平有正向影响,而对男性有负向影响。
然后,他们研究了特定蛋白质是否同时影响某些疾病和疾病相关特征,重点关注三个章节,包括代谢疾病和 NMR 代谢组学、痴呆和认知功能以及精神疾病和心理健康。他们发现特定蛋白质表现出与疾病的保护性关联以及对特征的有利影响。例如,IGFBP2 与较低水平的丙氨酸氨基转移酶 (ALT) 相关,以及较低的 T2D 风险(图 2 D)。IGFBP2 是已知的胰岛素敏感性生物标志物,并在纵向队列中证实为 T2D 的保护性蛋白。鉴于 ALT 水平升高与2型糖尿病风险增加有遗传相关性,他们观察到 IGFBP2 对 ALT 有有利影响,这可能进一步巩固其在 2 型糖尿病中的保护作用。他们还发现其他代谢物和相关疾病具有重叠蛋白质,包括尿酸和痛风、肌酸和慢性肾病(图2E-F)。流体智力和各种类型的痴呆症共有重要的蛋白质,如 NEFL 和 GDF15(图 2G),进一步支持这些蛋白质与认知功能之间的密切关系。焦虑症、抑郁症和情绪障碍等精神障碍以及与心理健康相关的特征也表现出显著的蛋白质相似性,包括 TNFRSF10A、GDF15、IGFBP4、WFDC2 等(图 2H)。值得注意的是,IGFBP4 已确定为情绪障碍的血液生物标志物。
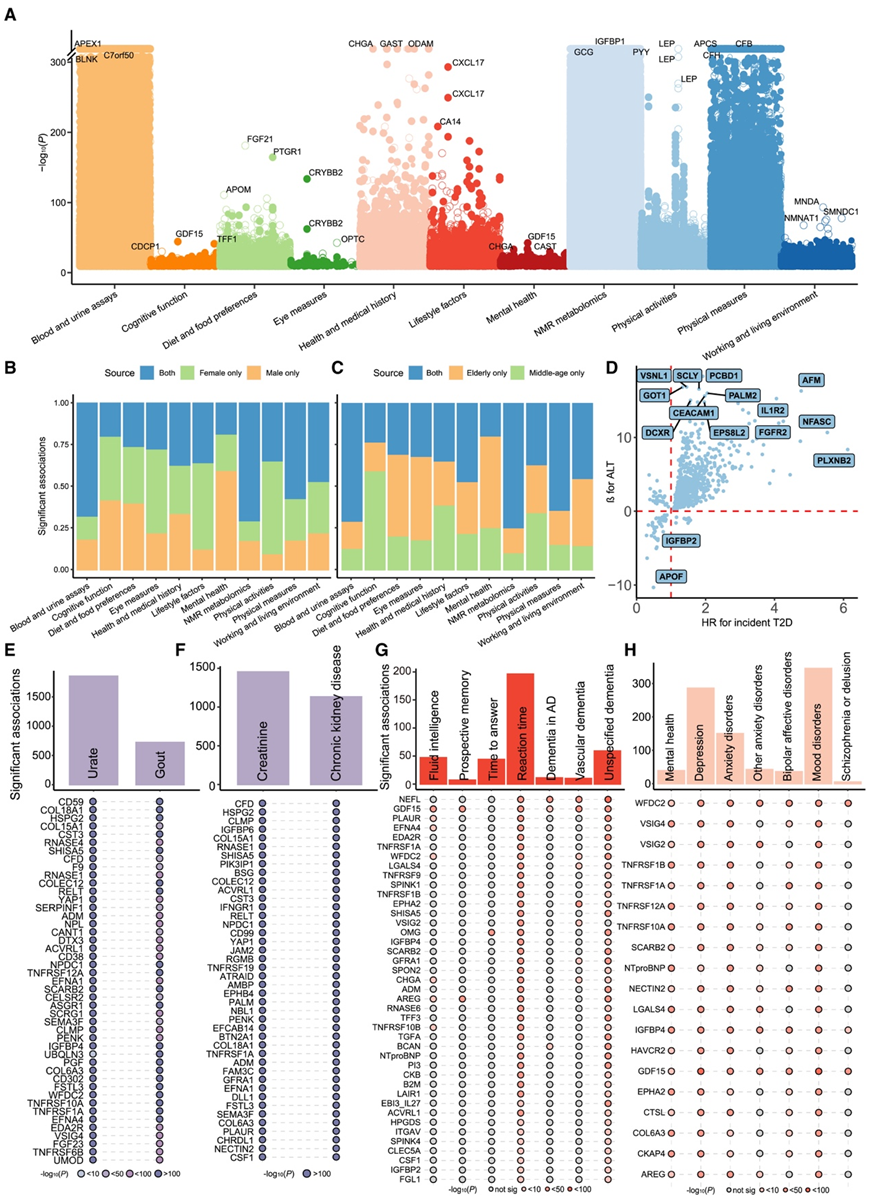
图2. 蛋白质-性状关联分析结果汇总及疾病与性状间的多效性。
(A) 蛋白质-性状关联,按性状类别着色。(B-C) 特征性别和年龄亚组分析中共有和特定显著关联的比例。(D) ALT 和 T2D 发病之间的共同蛋白质。(E-F) 尿酸和痛风以及肌酐和慢性肾病之间的共同蛋白质。(G) 认知功能特征与痴呆症亚型之间的共同蛋白质。(H) 心理健康特征与突发精神疾病之间的共同蛋白质。
03
疾病相关蛋白的生物学功能
为了加深对已鉴定蛋白质如何参与人类疾病的理解,他们对已鉴定蛋白质进行了一系列功能富集分析。在 660 种发病疾病中,539 种在至少一种 Reactome 通路中表现出显著富集。与免疫系统相关的通路在人类疾病中富集程度最高,尤其是在传染病和寄生虫病以及血液和造血器官、循环系统和呼吸系统疾病中(图 3A)。具体而言,TNF 与其生理受体的结合是与免疫系统相关的最常见通路,参与了除神经系统以外的各种系统中超过一半的疾病。这与在蛋白质流行疾病和蛋白质发病疾病关联中发现的 TNF 家族成员蛋白的广泛多效性一致,强调了炎症在人类健康中的重要作用。与蛋白质代谢相关的通路,包括翻译后磷酸化和胰岛素样生长因子的调节,在相当一部分疾病中也得到了富集。
比较不同疾病之间的生物学通路,可以加深对疾病病理生理相似性和异质性的理解。例如,他们发现与阿尔茨海默病 (AD) 和血管性痴呆 (VaD) 相关的蛋白质在与神经系统相关的共同通路中富集,包括突触成熟、神经元投射再生、中间丝组织、对施万细胞增殖的正向调节以及对轴突直径的调节(图 3 B)。同时,AD 特异性通路多与脂质代谢有关,包括调节跨血脑屏障的脂质转运和中密度脂蛋白颗粒清除,而 VaD 特异性通路与心肌有关,包括腺苷酸环化酶激活肾上腺素能受体信号通路和对心肌松弛的正向调节。
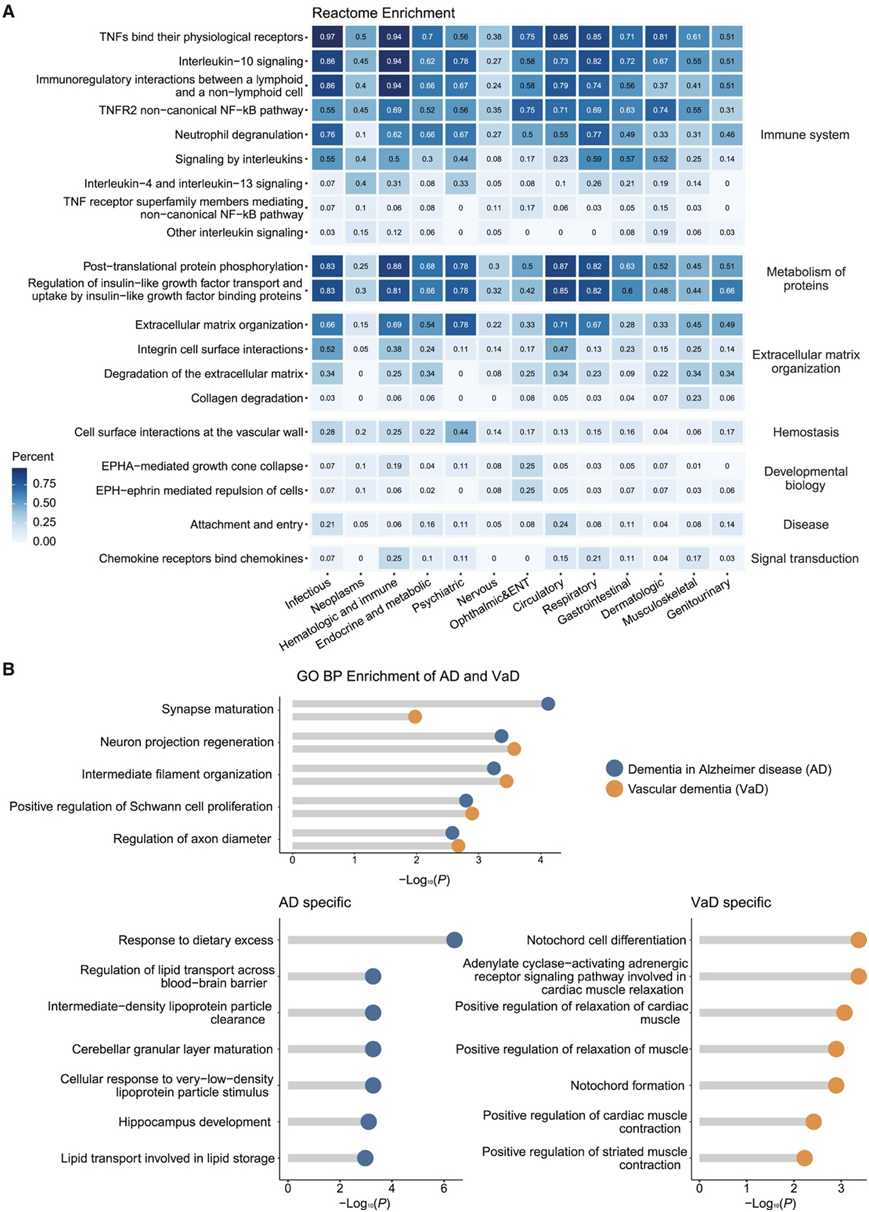
图3. 疾病相关蛋白的生物学功能。
(A) Reactome 通路富集分析结果按发病疾病章节进行分类。(B) GO-BP 富集结果与 AD 和 VaD 中的痴呆症相关蛋白的比较。
04
具有典型生物学特征的疾病群
他们根据蛋白质-疾病关联程度(即 HR)应用了层次聚类,并将 660 种疾病分为 40 个聚类。正如预期的那样,具有相似性的疾病进行分组并表现出特征性的生物学特征(图 4 A)。例如,聚类1 包括肝纤维化和肝硬化及其并发症,如门脉高压症和食管静脉曲张(图 4 B)。这些疾病主要通过小蛋白质去除、酒精代谢和涉及神经系统和细胞形态发生的途径进行蛋白质修饰,表明潜在的机制包括去泛素化、饮酒和上皮-间质转化及其对神经系统的影响。聚类39由非霍奇金淋巴瘤亚型组成,其特征是包括 B 细胞活化在内的通路(图 4 C)。聚类 32 主要包括糖尿病引起的神经系统并发症,显示出对涉及神经系统的通路的重大影响。
涉及免疫系统、细胞发育、对刺激的反应和细胞活化的通路在大多数聚类中表现出一致的变化(图 4 A),这些通路可能在大多数疾病中发生激活。虽然方向性变化一致,但各聚类之间通路得分的不同幅度意味着聚类特异性(图4A)。某些通路如果在大多数疾病中一致,则不会突出显示,即使它们可能在特定疾病中上调。
有趣的是,60% 的聚类包含来自多个疾病类别的疾病。以聚类30 为例(图 4 D),它包括来自血液和造血系统、神经系统、呼吸系统、肌肉骨骼系统和结缔组织的疾病。其特征途径包括蛋白质转运、细胞周期过程、小 GTP 水解酶 (GTPase) 介导的信号转导、分解代谢过程、自噬和酰胺生物合成过程。
他们分析了每个聚类的多重患病状态,即每个个体在每个聚类中发病的疾病数量。然后,应用有序回归模型来研究与多重患病水平相关的蛋白质。对于 36 个聚类,在纵向分析中,超过一半与多重患病水平相关的蛋白质也与聚类内至少一种疾病显著相关。这从种群角度反映了聚类内疾病的相似生物学特征,并强调了共有蛋白质的重要性。
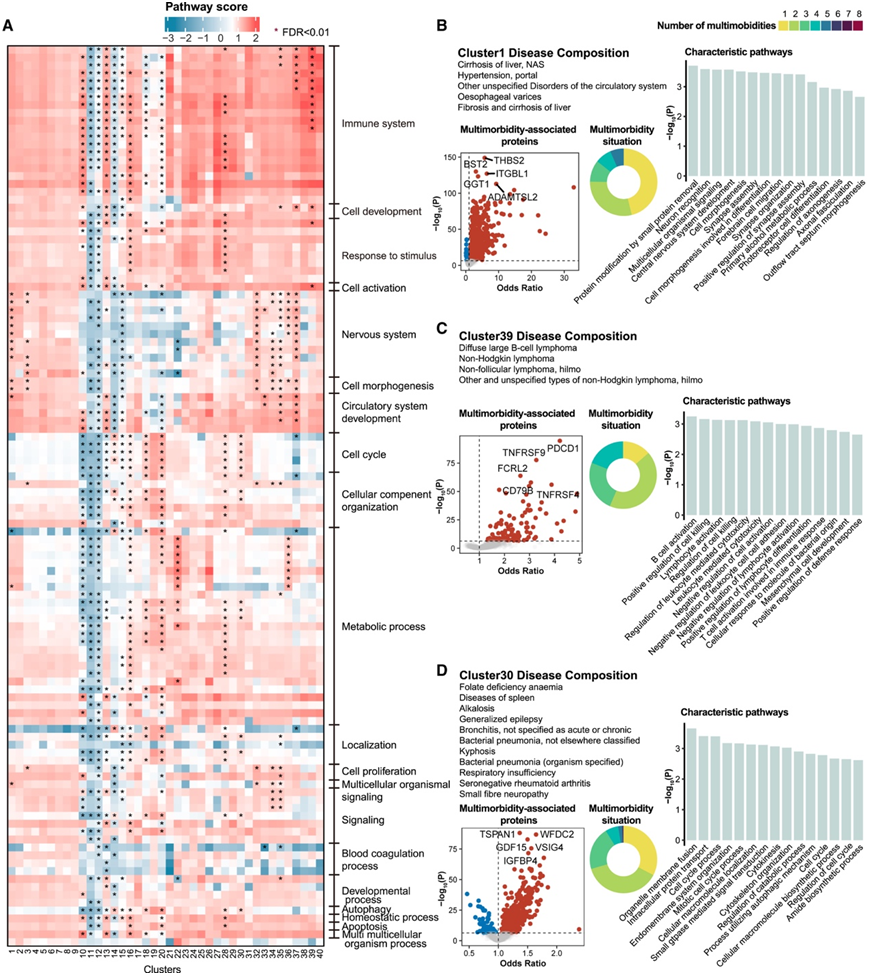
图4. 40 个疾病聚类和选定示例的典型生物学特征。
(A) 将 660 种疾病的蛋白质组分类为 40 个聚类。热图显示了通过基因集富集分析检测到的疾病聚类中 GO BP 基因集的富集情况。(B) 聚类1、39 和 30 的示例显示了 (A) 中的疾病组成、多重患病情况、与多重患病相关的蛋白质以及聚类的特定特征通路。
05
蛋白质有助于疾病诊断和预测
通过为每个终点建立疾病风险模型,他们研究了蛋白质、人口统计学特征及其整合的诊断和预测价值。对于疾病预测,基于蛋白质的模型对 13 个疾病类别中的 92 种疾病(13.9% = 92/660)表现出良好的曲线下面积 (AUC),超过 0.80,其中大多数是内分泌和代谢疾病和循环系统疾病(图 5 A)。特别值得注意的是,基于蛋白质的模型对 9 种疾病给出了出色的预测(AUC > 0.9),例如伴有外周循环并发症的 2 型糖尿病、高血压肾病、慢性肾病综合征、透析和背景糖尿病视网膜病变。基于蛋白质的模型在预测 361 种特定疾病时表现出比人口统计模型更好的准确度。特别是在预测糖尿病肾病、乳糜泻和甲状旁腺功能亢进症时,基于蛋白质的模型表现出明显优于基于人口统计学的模型,但其表现与结合蛋白质和人口统计学的模型相当。在预测便秘和膈疝等疾病时,基于蛋白质的模型的表现明显优于人口统计学模型。此外,将血浆蛋白整合到人口统计学中可显著提高 417 种 (63.2%) 疾病的预测准确率。
对于疾病诊断,基于蛋白质的模型对 14 个疾病类别中的 124 种疾病表现出超过 0.80 的高 AUC,其中循环系统疾病和内分泌和代谢疾病在疾病诊断方面始终表现出良好的性能。此外,基于蛋白质的模型在 36 种疾病的诊断中实现了超过 0.9 的优异 AUC,尤其是在 1 型糖尿病 (T1D)、糖尿病性黄斑病变、慢性肾病、T2D、高血压肾病、心肌梗死和背景糖尿病视网膜病变中(图 5 B)。这些结果强调了与基于人口统计学的模型相比,基于蛋白质的模型具有更优异的判别性能。在神经、神经根和神经丛疾病、泌尿生殖系统疾病和软组织疾病等疾病的诊断方面,基于蛋白质的模型的表现明显优于人口统计学模型。基于蛋白质的模型在诊断 218 种特定疾病方面优于人口统计学模型。将血浆蛋白整合到人口统计模型中后,观察到 253 种 (62.3%) 疾病的诊断准确率显著提高。
他们计算了血浆蛋白在预测和诊断疾病中的重要性。这有助于识别与每种疾病相关的关键鉴别因素(前 30 名)。蛋白质 GDF15在预测和诊断多种疾病中起着关键作用。具体来说,GDF15 是预测性蛋白质,在最多数量的疾病中排名最高。紧随 GDF15 之后的是 EDA2R、NTproBNP、COL9A1 和 NEFL,分别在 21、19、15 和 14 种疾病中占据首位(图 5 C)。在疾病诊断方面,GDF15 也成为在最多疾病中排名第一的蛋白质,其次是 PAEP、CHGA、REN 和 COL9A1,分别在 27、20、20 和 15 种疾病中排名第一(图 5 D)。此外,在排名第一数量最多的前 10 种蛋白质中,有 5 种(即 GDF15、WFDC2、NTproBNP、EDA2R 和 PAEP)在诊断和预测模型之间重叠,强调了它们在诊断和预测疾病方面良好的判别性能。有趣的是,预测模型中排名前十的蛋白质中的 6 种蛋白质(即 GDF15、WFDC2、NTproBNP、NEFL、COL9A1 和 GFAP)在蛋白质事件疾病分析中也排名前十,表明 Cox 模型和机器学习方法在疾病生物标志物的识别方面是一致的。
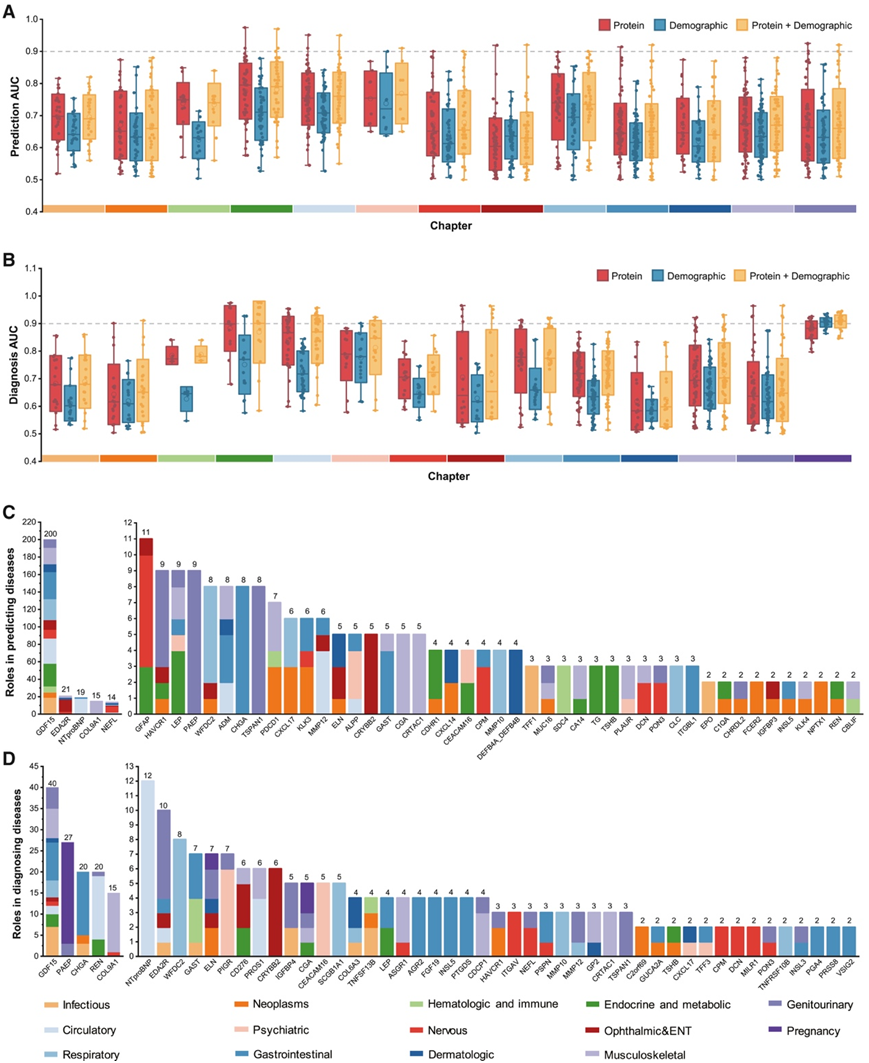
图5. 蛋白质对疾病预测和诊断的贡献。
(A-B) 基于三种模型(蛋白质、人口统计学和蛋白质+人口统计学)的蛋白质在预测和诊断中的判别性能。(C-D) 堆叠条形图,显示蛋白质在预测和诊断疾病中的作用。
06
疾病的潜在致病蛋白
利用 UKB 中的大量遗传信息,他们研究了与流行和发病疾病相关的蛋白质是否在疾病过程中起因果作用或只是疾病的结果,从而有助于理解疾病的发病机制和确定潜在的药物靶点。使用 pQTL 数据和疾病的全基因组关联研究 (GWAS) 汇总数据,对显著的蛋白质-疾病关联进行孟德尔随机化 (MR) 分析。在以顺式pQTL 作为“暴露”、以疾病 GWAS 作为“结果”的顺式-MR 分析中,178 种蛋白质流行疾病和 185 种蛋白质发病疾病对显示出潜在的因果关系。反式MR分析还分别从蛋白质流行性疾病和蛋白质发病疾病关联中确定了 198 和 199 个潜在因果对。排除冗余对和在反向 MR中同样重要的对后,他们确定了 474 个独特的潜在因果蛋白质-疾病对,其中七个蛋白质显示出十个或更多的潜在因果对,包括 SEMA3F、SERPINF1和 PCSK9(图 6 A)。
这些结果为已确定的蛋白质-疾病关联提供了因果证据,并发现了相关的遗传变异。例如,具有多效性的蛋白质 GDF15 与多种自身免疫性疾病有因果关系,包括溃疡性结肠炎和类风湿性关节炎(图 6 B)。自身免疫多效性 SNP rs4728142与较高的血浆 GDF15 水平相关,验证了 GDF15 可能促使自身免疫性疾病发病的假设。此外,大多数的因果蛋白质是在循环系统疾病和内分泌和代谢疾病中发现的,高血压位居榜首(图 6 C)。蛋白质 FURIN 与高血压表现出最显著的关联,其次是心绞痛、冠心病和缺血性心脏病(图 6D),这与最近关于 FURIN 在心血管疾病中的作用的研究结果一致。
除了通过研究潜在的因果关系为疾病的发病机制提供线索之外,他们还确定了 4,014 个疾病-蛋白质对,其中蛋白质的变化可能是某些疾病的结果(图 6 E)。发现血浆中 PLAUR 水平较高与 6 个系统的 18 种疾病有关(图 6 F),其中 7 种是肝脏疾病,例如肝纤维化和肝硬化。在肝纤维化进展过程中,尿激酶纤溶酶原激活剂表面受体 PLAUR 参与炎症反应、血管稳态和免疫调节。这也反映在血浆 PLAUR 水平与白细胞计数和 CRP之间的显著关联。有趣的是,他们发现 EDA2R 和 GDF15 也可能是肝硬化、慢性阻塞性肺病 (COPD) 和慢性肾病等疾病的结果(图 6G-H),反映了某些器官的病理。

图6. 潜在因果蛋白质总结。
(A) 潜在致病蛋白的堆积条形图。(B-D) MR 分析的显著结果,包括 (B) GDF15 与自身免疫性疾病、蛋白质与高血压以及FURIN 与心血管疾病。(E) 因某些疾病而产生的蛋白质的堆积条形图。(F-H) 疾病和PLAUR、EDA2R 和GDF15 的 MR 分析的显著结果。
07
药物靶标验证和重新定位
鉴于血浆蛋白是药物靶标的主要来源,他们试图挖掘已识别的疾病相关蛋白,以寻找未来药物开发的有希望的靶标。在 1,648 种流行疾病相关蛋白和 2,013 种偶发疾病相关蛋白中,分别有 1,029 种(62.4%)和 1,124 种(55.8%)与 公开的可成药基因组(druggable genome)重叠。此外,编码这些疾病相关蛋白的基因集富含可成药基因(流行疾病的 OR 为 1.74,偶发疾病的 OR 为 1.32)(图7A)。这些疾病相关蛋白与可成药基因之间存在相当大的重叠(尤其是对于第 1 层,其中包括已获批准的小分子和生物治疗药物以及临床阶段候选药物的功效靶标)。
先前的研究已经强调了利用遗传学进行药物开发和重新定位的机会。因此,他们进一步将来自顺式-MR 分析的具有因果证据的药物与两个药物数据库(即 DrugBank 和治疗靶点数据库)中的靶点-适应症对进行了比较。在具有因果联系的171对蛋白质流行疾病对和 170 对蛋白质发病疾病对中,分别有 32%(54 对)和 22.4%(38 对)有批准或临床试验药物(图 7 B)。例如,数十种针对 ACE 的药物(如卡托普利、依那普利拉和福辛普利)已批准用于治疗高血压。此外,他们发现了 25 个已建立药物靶点的 37 个重新利用机会,例如用于治疗抑郁症的 BSG。
安全性也是靶点评估和药物开发的一个关键方面。使用开放式数据库(AD Knowledge Portal),他们评估了按顺式-MR 分析优先排序的123 个潜在靶点的安全性。十个靶点(例如,EPHA2)的风险最低(药物处于 IV 期试验阶段;安全性等级为 1)。六个靶点(例如,MMP12)的风险较低(从基因表达或遗传或药理学分析中未发现重大问题,但尚未在人体上进行广泛测试;安全性等级为 2)。二十六个靶点(例如,SEMA3F)具有潜在风险(高脱靶基因表达、癌症驱动因素、必需基因、相关的有害遗传疾病、人类表型本体 [HPO] 表型相关基因或临床使用药物的黑框警告中有两个或更少;安全性等级为 3)。 76 个靶点(例如 BSG)具有可能的风险(具有超过两个的高脱靶基因表达、癌症驱动基因、必需基因、相关的有害遗传疾病、HPO 表型相关基因或临床使用药物的警告;安全性等级为 4)。五个靶点(例如 F10)对人类有潜在不安全因素(具有靶向药物不良反应和撤回药物;安全性等级为 5)(图 7 C)。值得注意的是,顺式-MR 研究结果优先考虑了 26 个具有良好安全性(安全性量表 ≤ 3)的未确定潜在治疗靶点,以供未来药物开发。
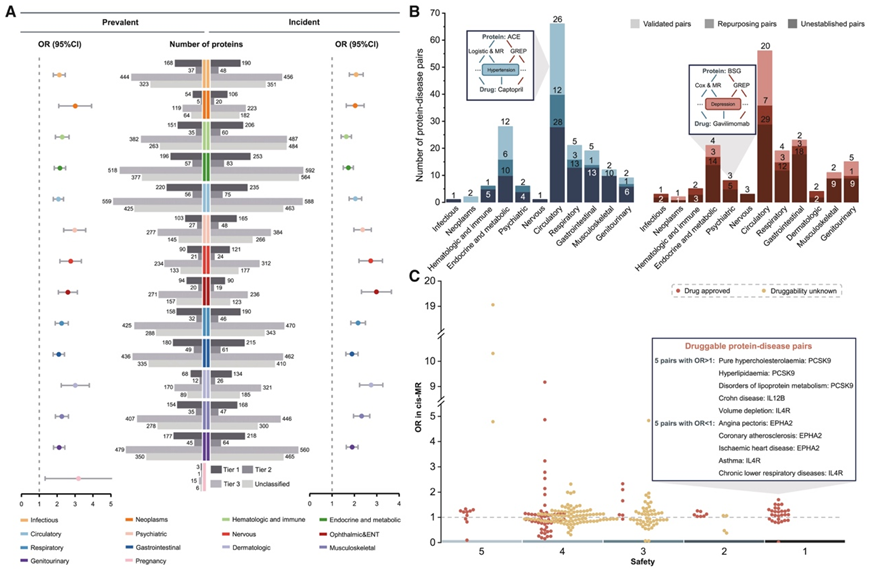
图7. 药物靶标验证、重新定位和识别。
(A) 利用可用药基因组富集蛋白质。(B) 将顺式-MR 发现与 DrugBank 和治疗靶点数据库中的靶标-适应症对信息进行比较。(C) 潜在靶标的安全性、因果关系和可用药性。
+ + + + + + + + + + +
结 论
本项研究提供了英国生物库中 53,026 人(中位随访期:14.8 年)中与疾病(406 种流行疾病和 660 种发病疾病)和 986 种健康相关性状相关的 2,920 种血浆蛋白的详细图谱,代表了迄今为止最全面的蛋白质组谱。该图谱揭示了 168,100 种蛋白质与疾病的关联和 554,488 种蛋白质与性状的关联。至少 50 种疾病共有 650 多种蛋白质,1,000 多种蛋白质表现出性别和年龄异质性。此外,蛋白质在疾病鉴别方面表现出良好的潜力(183 种疾病的曲线下面积 [AUC] > 0.80)。最后,整合蛋白质数量性状基因座数据确定了 474 种致病蛋白,提供了 37 种药物再利用机会和 26 种具有良好安全性的有希望的靶点。这些结果提供了一个开放获取的综合蛋白质组-表型组资源,有助于阐明疾病的生物学机制并加速疾病生物标志物、预测模型和治疗靶点的发展。
+ + + + +



