

 English
English文献解读|Nat Commun(15.7):大规模血清N-糖组学追踪肝细胞癌进展过程中N-糖基化的动态变化,并有助于早期诊断
✦ +
+
论文ID
原名:Large-scale serum N-glycomics tracks N-glycosylation dynamics in hepatocellular carcinoma progression and enables early diagnosis
译名:大规模血清N-糖组学追踪肝细胞癌进展过程中N-糖基化的动态变化,并有助于早期诊断
期刊:Nature Communications
影响因子:15.7
发表时间:2026.01.20
DOI号:10.1038/s41467-026-68579-x
背 景
肝细胞癌 (HCC) 是癌症死亡的主要原因之一,但N-糖基化在其发病机制中的作用尚不明确。许多循环液体活检肿瘤生物标志物,例如ctDNA、cfDNA、代谢物和蛋白质,正在迅速发展。蛋白质糖基化的研究尤其受到关注。既往研究已充分证实,蛋白质糖基化的改变在肝脏疾病和恶性肿瘤的发生和发展中起着至关重要的作用。血清糖组学,尤其是血清N-糖组学,已证明是发现肝脏疾病生物标志物的一种很有前景的策略,因为血清中发现的大多数N-聚糖都与肝脏分泌的蛋白质相关。肝脏稳态的紊乱会导致肝细胞高尔基体和内质网中糖基化相关酶的失调。因此,N-糖组学改变可能反映肝功能紊乱,或作为AFP的补充监测或诊断价值的生物标志物。
实验设计
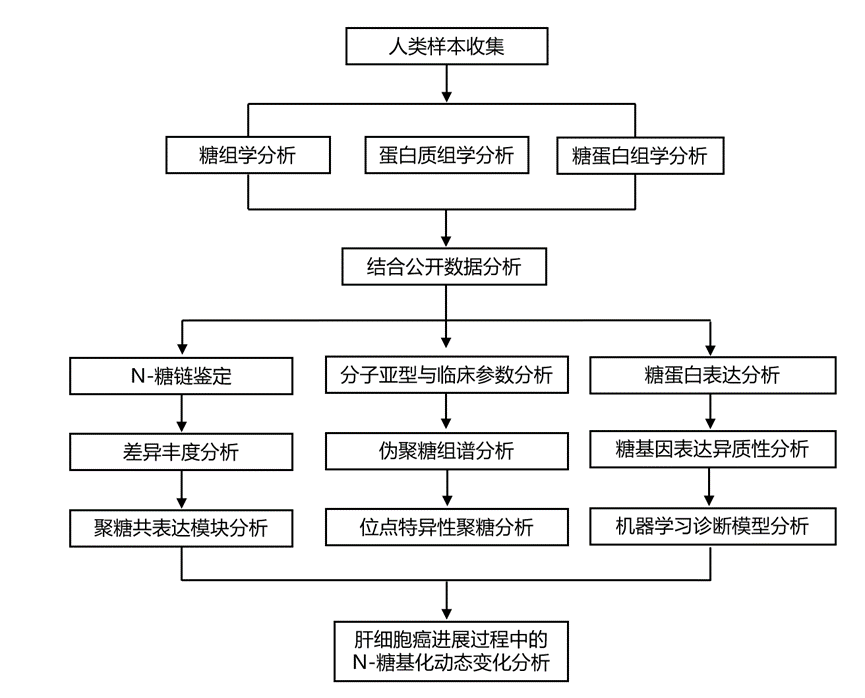
结 果
01

研究设计、数据收集、数据质量和N-糖组概述
研究纳入了三个独立的队列(发现队列广州-I,GZ-I,n = 744;外部验证队列广州-II,GZ-II,n = 186;以及徐州,XZ,n = 144),涵盖了健康对照组和不同肝病阶段。共招募了1074名参与者。所有参与者的血清N-糖组均采用MALDI-TOF MS进行分析。GZ-I队列的一个子集(n = 120)用于基于LC-MS的N-糖蛋白组学和蛋白质组学分析。他们使用GZ-I队列的另一子集(n = 186)进行唾液酸连接特异性N-糖组学分析。GZ-I队列用于生物信息学分析、模型训练和内部模型验证,而GZ-II队列和XZ队列用于外部模型验证(图1)。
肝功能检查(LFT)是评估肝脏健康和诊断肝脏疾病的重要临床工具。他们研究了血清N-糖组谱与肝功能检查以及两种已建立的肝功能评分系统(LFSS)——白蛋白-胆红素(ALBI)分期和Child-Pugh分级之间的关联(图 2a)。结果显示,N-糖组谱与肝功能检查(图 2b)和肝功能评分系统(图 2b)均存在显著相关性。值得注意的是,ALBI评分作为肝功能和肝病预后的现代指标,与多种N-糖链表现出强相关性。为了全面表征N-糖组,他们计算了与生物合成途径相关的衍生特征,包括分支、二分 GlcNAc、岩藻糖基化、半乳糖基化和唾液酸化。肝功能较差与分支、二分 GlcNAc 和岩藻糖基化增加以及半乳糖基化和唾液酸化减少相关(图 2c-d)。
为了消除不同肝病混杂因素的影响,他们针对每种疾病队列进行了亚组相关性分析。这些分析证实了血清N-聚糖谱与肝功能之间存在显著关联,尤其是在肝硬化(LC)和HCC患者中。相关性模式在整体和亚组水平上均保持一致,LC和HCC队列的一致性尤为显著,ALBI评分也证实了这一点(图2e-f)。这表明N-聚糖可以作为评估肝功能的可靠标志物。他们构建了一个基于N-聚糖谱预测ALBI分期的随机森林模型,进一步支持了这一结论,该模型的受试者工作特征曲线下面积。预测概率与实际ALBI评分高度吻合。这些结果表明,血清N-糖组谱能够有效反映肝功能恶化。
图1. 研究设计和工作流程概述。
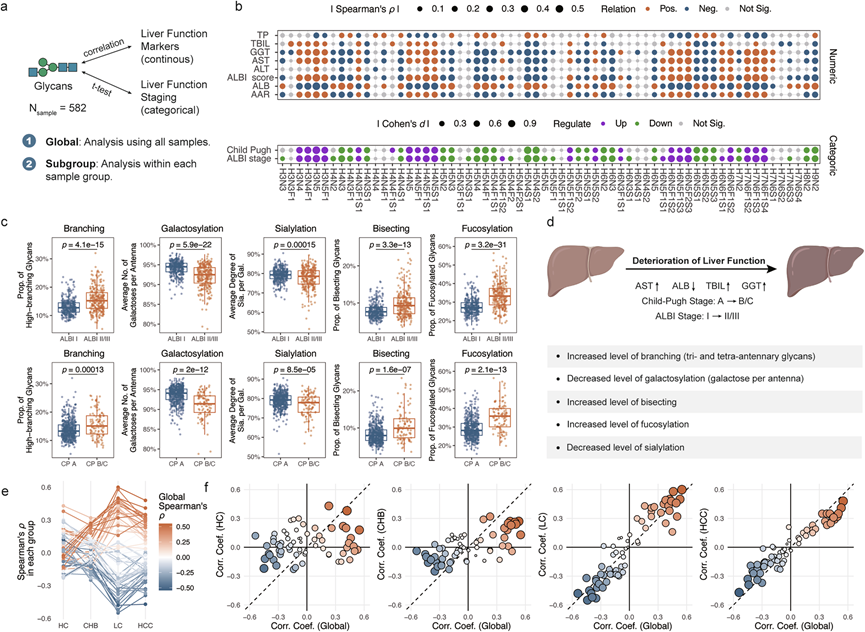
图2. 血清N-糖与肝功能的关系。
(a) 用于评估血清N-糖组学与肝功能之间关系的统计方法示意图。(b) 热图描绘了糖组与肝功能检查(LFT)及肝功能评分系统统计分析的效应量。(c) 关键N-糖组衍生特征。(d) 总结了与肝功能恶化相关的N-聚糖组学改变。(e) ALBI评分与N-聚糖丰度之间的Spearman秩相关系数。(f) 散点图比较了每种疾病组的Spearman相关系数与整体相关系数。
02
血清N-糖组改变与肝细胞癌的发生发展平行
差异丰度分析鉴定出64种N-聚糖中有48种在不同疾病组中显著失调(图 3a-c)。HCC对血清N-聚糖组谱的影响最为显著(图 3c),其次是肝硬化(图 3b)。相比之下,慢性肝炎中仅观察到 少数显著的N-糖基化改变(图3a)。在肝硬化中,下调的N-聚糖主要为三触角和四触角、多唾液酸化且缺乏岩藻糖基化的结构(图 3b)。相反,HCC的特征是类似的、具有岩藻糖基化的三触角和四触角、多唾液酸化聚糖的上调(图 3c)。值得注意的是,这些岩藻糖基化、多唾液酸化的三触角和四触角聚糖在 HCC 中特异性上调,而在肝硬化中基本保持不变(图 3d)。
根据表达模式,将48个显著异常表达的N-聚糖分为五个聚糖共表达模块(GCM)(图3e)。每个GCM均表现出独特的表达谱(图 3f)和富集的结构特征(图 3g),表达相似性较低(图 3h)。例如,GCM1由岩藻糖基化、完全唾液酸化的三分支和四分支聚糖组成,仅在HCC中上调。相反,GCM2由其非岩藻糖基化的对应物组成,在肝硬化中下调。GCM3主要由带二平分型N-乙酰氨基葡萄糖(GlcNAc)的较小聚糖组成,在肝硬化和HCC中均上调。值得注意的是,GCM4包含两个杂合的单唾液酸化聚糖,在所有肝脏疾病中均上调,但在HCC中的上调程度较低。最后,由大量高甘露糖、混合或未成熟复合聚糖组成的 GCM5 仅在 HCC 中下调。
在各种肝脏疾病中均观察到血清N-糖组的特征性结构改变(图 3i)。双触角糖链在HCC中表达下调,而三触角和四触角糖链表达上调。此外,半乳糖基化水平降低,而二分N-乙酰氨基葡萄糖和岩藻糖基化水平在肝硬化和HCC中均升高。利用唾液酸连接特异性衍生化方法,他们发现肝硬化中α2,6-连接的唾液酸化特异性下调。
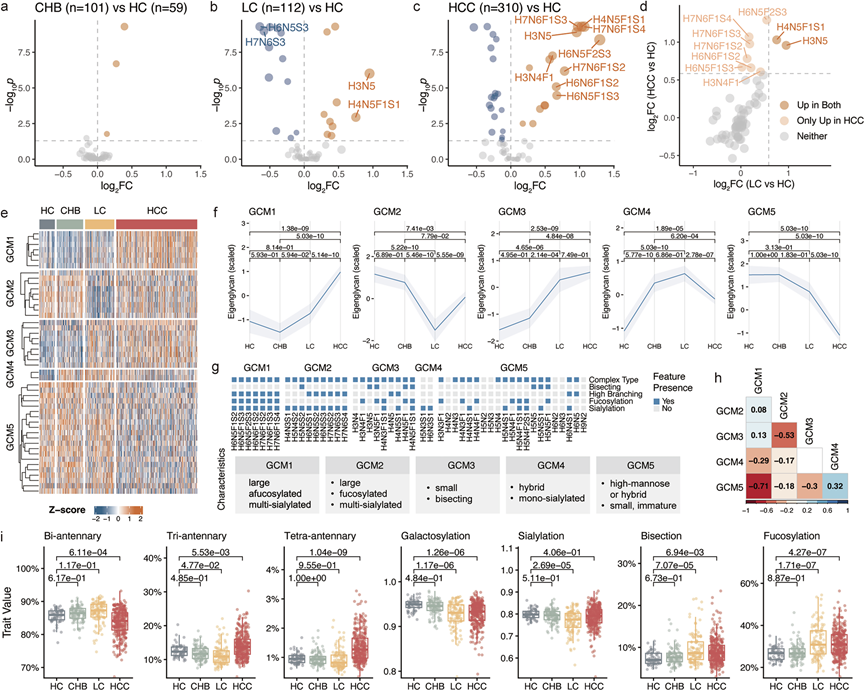
图3. 血清N-糖组与肝脏疾病相关。
(a-c) 分别展示了CHB(n = 101)和HC(n = 59)、LC(n = 112)和HC以及HCC(n = 310)和HC之间显著糖基化的火山图。(d) 比较了HCC和LC中表达失调的糖基化位点。(e) 将糖基化位点聚类为五个糖基化共表达模块(GCM)。(f) 每个GCM中特征糖基化位点的趋势。(g) 各糖基化复合体 (GCM) 中聚糖的结构特性。(h) GCM特征聚糖的相关性。(i) 关键衍生性状的分布。
03
具有不同临床特征的N-糖组亚型
分子分型是精准医学的基石,它通过N-糖组谱等生物标志物对异质性疾病进行分层。对血清N-糖组数据进行无监督共识聚类分析,将HCC样本分为三个不同的亚型(图 4a)。每个亚型都表现出独特的N-糖谱(图 4b)。亚型1的特征是小的、未成熟的糖链水平升高,包括GCM3中含有二分N-乙酰氨基葡萄糖(GlcNAc)的糖链,以及GCM2中大的、多唾液酸化的、无岩藻糖基化的糖链水平降低(图 4c,图 3g)。亚型2的特征是GCM1中大的、多唾液酸化的、岩藻糖基化的糖链水平降低。亚型 3 表现出 GCM1 聚糖增加,同时 GCM5 中高甘露糖、混合型或小复杂型聚糖水平降低,呈现出与亚型 1 部分互补的糖组学特征。与对照组(健康对照组、慢性乙型肝炎和肝硬化)相比,亚型 2 表现出与非 HCC 状态非常相似的 血清N-糖组学模式,表明其具有早期癌表型。
N-糖组分子亚型与临床参数之间存在显著关联。与亚型2相比,亚型1和3的肝功能较差,这体现在包括AST、ALT、GGT、ALB、TBIL、TP、ALBI评分和AAR在内的肝功能指标上。这与亚型2的N-糖组特征相符,该特征更接近对照组。N-糖基化亚型与已建立的临床分期系统也表现出显著的重叠性,包括Child-Pugh分级、ALBI分期和TNM分期。值得注意的是,亚型2的患者主要处于早期病理阶段,表明该亚型代表一种疾病进展程度较低、肝功能相对保留的状态。亚型1和亚型3在肝功能或癌症分期方面没有显著差异,但表现出完全不同的糖基化模式。这可能提示存在不同的潜在疾病机制,值得在未来的研究中进一步探讨。
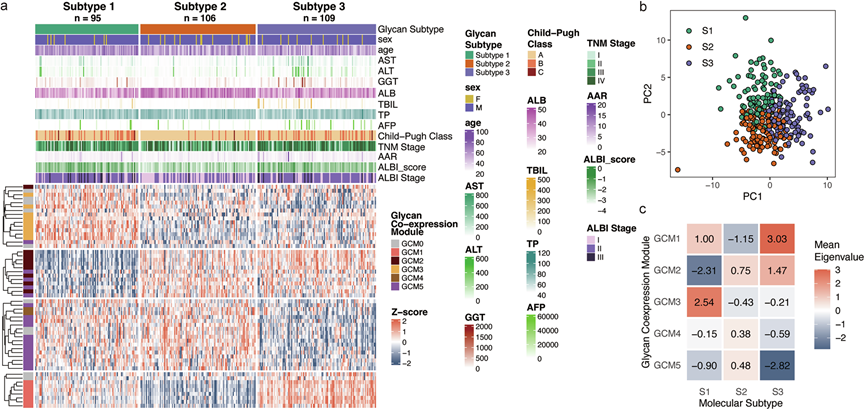
图4. N-聚糖亚型热图。
(a) 热图展示了三种亚型的表达模式。(b) 不同 HCC 亚型的 PCA 图。(c) 不同亚型中 GCM 的特征糖链。
04
绘制血清中位点特异性N-糖基化模式图谱
之前的分析已经描述了与肝病进展相关的整体N-糖组变化,但一个关键问题仍然存在:位点特异性糖基化事件如何共同影响血清糖组?为了解决这个问题,他们对GZ-I队列的一个子集(n = 120,每组30例)进行了正交的N-糖蛋白组学和蛋白质组学分析,采用DDA 精确模式,以应对两个关键挑战:(1)确定糖组变化是由糖基化酶活性改变(位点水平调控)还是糖蛋白丰度变化(整体蛋白质组变异)引起的;(2)鉴定疾病相关聚糖的主要糖蛋白载体。他们鉴定了3057个糖肽、2824个位点特异性聚糖、477种聚糖组成、276个糖基化位点和168个糖蛋白(图S16a)。在蛋白质组学数据中检测到的961个蛋白质组中,有107个与糖蛋白组学中鉴定的蛋白质组重叠(图S16b)。此外,在糖组学数据中检测到的201个聚糖中,有148个也在糖蛋白组学中鉴定出来(图S16c)。
他们通过汇总所有具有相同聚糖组成的位点特异性聚糖的定量数据,生成了伪聚糖组谱(图 5a)。这些伪聚糖组谱与实际聚糖组谱高度一致,平均皮尔逊相关系数(r)约为0.95。需要注意的是,伪聚糖组谱代表了一种通过汇总不同蛋白质和糖肽的信号进行估计的策略,而非严格的定量方法。该方法展示了在位点特异性水平上解读聚糖组学表型的潜力,并可利用糖蛋白组学作为补充工具。值得注意的是,聚糖表现出多种位点特异性贡献(图 5b-d)。例如,血清N-糖组中最丰富的聚糖H5N4S2显示出来自多个糖基化位点的均匀贡献(图 5b)。相比之下,H5N5F1S1主要与IGHM N46和IGHA2 N92(或IGHA2 N207)相关(图 5c)。具有相似结构特征的聚糖表现出相似的位点贡献(图 5d)。例如,三触角和四触角、岩藻糖基化、多唾液酸化的聚糖主要来源于A1AG1 N93,而未成熟的、无半乳糖基化的复杂或混合聚糖主要与IGHG1 N180(或IGHG1 N299)相关。这些发现揭示了血清N-糖组中位点特异性贡献的异质性,这种异质性主要由一组高丰度糖蛋白驱动。
他们对位点特异性聚糖(SSG)进行了差异分析,仅选择那些在与其对应蛋白丰度无关的情况下表现出显著改变的SSG(图 5e-g)。结果显示,在慢性乙型肝炎(CHB)、LC和HCC样本中,分别有67、148和114个SSG显著上调,而分别有63、124和73个SSG下调(图 5h)。通过整合糖组学和糖蛋白组学数据,阐明了糖组学改变的两种不同机制:(1)糖基化主导机制和(2)蛋白主导机制。糖基化主导机制表明,某些糖组学改变源于上游糖基化途径的失调。例如,H5N3S1是一种单唾液酸化的杂合聚糖,在所有肝脏疾病的糖组学数据中均有升高,尤其是在CHB中(图3f-g)。H5N3S1主要与α2-巨球蛋白(A2MG)的N869位点相关(图 5i)。对该位点的进一步分析显示,虽然肝脏疾病进展过程中整体A2MG水平仅略有升高,但CHB中H5N3S1的含量却显著增加(图 5j)。这表明N-糖基化失调本身如何驱动表型N-糖组的变化。另一方面,在以蛋白质为主导的机制中,某些高丰度糖蛋白表达水平的改变,即使在上游糖基化调控通路未发生改变的情况下,也会对观察到的糖组产生不可忽视的影响。例如,四触角、岩藻糖基化、多唾液酸化的聚糖(H7N6F1S2、H7N6F1S3 和 H7N6F1S4)水平的升高,主要由急性期免疫蛋白 A1AG1 的升高驱动。这凸显了未来糖组学研究的一个重要方向,即仅凭血清糖组学数据可能不足以提供调控机制的深入见解。
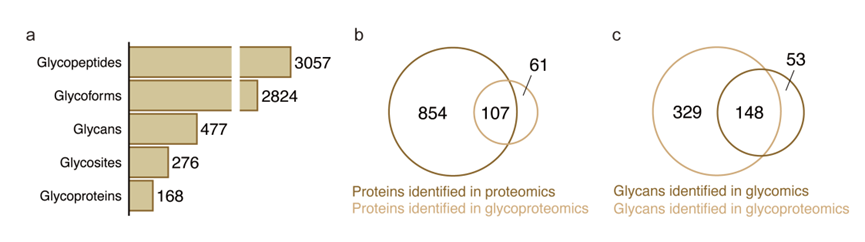
图S16. 糖蛋白组学结果概述。
(a) 条形图显示在糖蛋白组学分析中鉴定的糖肽、糖型、聚糖、糖位点和糖蛋白的总数。(b) 维恩图说明在蛋白质组学和糖蛋白质组学数据集中鉴定的蛋白质重叠。(c) 维恩图描绘了在糖组学和糖蛋白组学数据集中鉴定的聚糖的重叠。
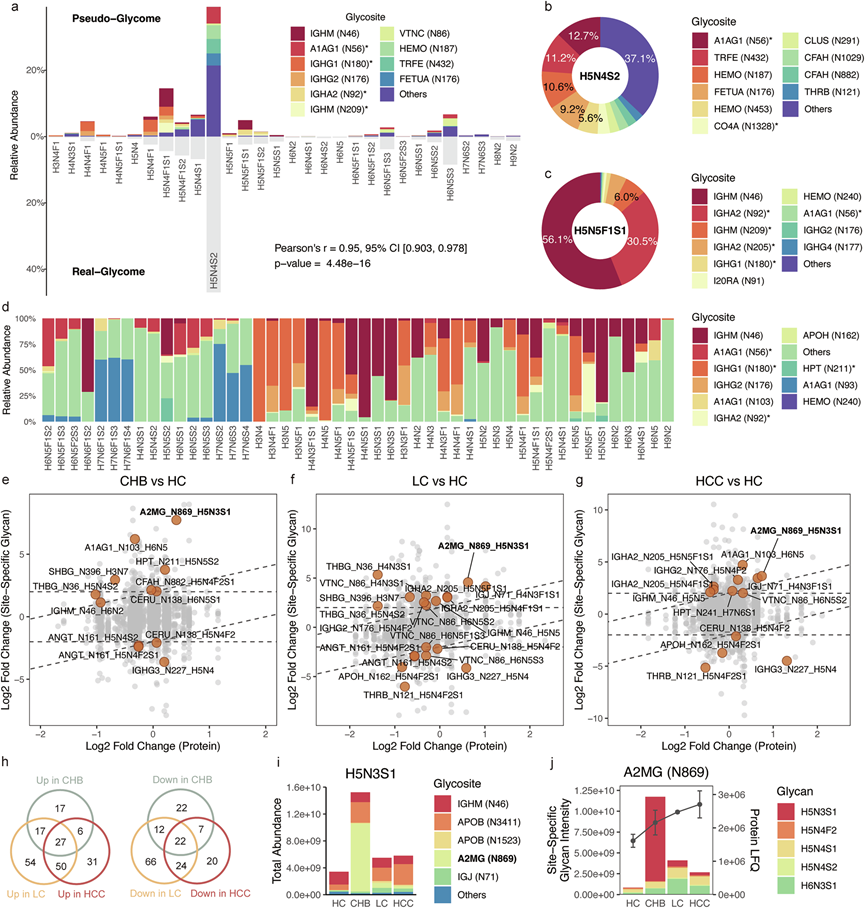
图5. 位点特异性聚糖数据分析。
(a) 混合HC样本的假糖组与真实糖组的比较。(b) 糖链H5N4S2的位点贡献。(c) 糖链H5N5F1S1的位点贡献。(d) 所有糖链的位点贡献在整体糖组学数据中各组间均显示出显著差异。(e-g) 位点特异性糖链和整体蛋白丰度的变化比较。(h) 失调SSG汇总。(i) 四个组中H5N3S1的平均位点贡献。(j) A2MG N869 位点特异性聚糖的平均丰度和 A2MG 的无标记定量 (LFQ)。
05
N-糖基化相关酶和调节因子的改变
蛋白质N-糖基化是一个高度调控的过程,包括起始、修饰或加工、分支和延伸以及末端修饰等一系列步骤,这些步骤由内质网和高尔基体中多种糖基转移酶、糖苷酶和其他调节因子的有序作用控制。为了解这些酶和调节因子的改变是否参与驱动HCC中观察到的N-糖基化变化,他们分析了TCGA-LIHC数据集中的基因表达数据,重点关注Reactome数据库中 注释为参与人类N-糖基化通路的307个基因。在肿瘤肝组织中观察到糖基化相关基因普遍上调(图 6a)。一小部分肿瘤表现出与健康组织相似的糖基因表达模式,这表明HCC肿瘤中糖基化存在异质性。
差异表达分析 (DEA) 显示,有 118 个糖基化基因上调,仅有 2 个糖基化基因下调(图 6b),表明肿瘤细胞中N-糖基化总体增强。值得注意的是,DPAGT1 是一种关键酶,催化 GlcNAc 向多萜醇磷酸的转移,这是N-聚糖生物合成的初始步骤,其表达显著上调(1.9 倍)。同样,负责组装脂质连接的寡糖前体的多个 ALG 家族基因(例如 ALG1/3/5/6/12)的表达水平也升高。寡糖基转移酶 (OST) 复合物对于将聚糖前体转移到新生多肽上至关重要,其表达也显著上调。催化亚基STT3A的表达量增加了2.3倍,其他OST亚基,包括DDOST、RPN1、RPN2和TUSC3,也表现出显著的过表达。这表明肿瘤细胞可能增强了N-糖基化的效率,从而促进了更多种类糖蛋白的糖基化。与此同时,介导糖蛋白折叠质量控制的内质网驻留分子伴侣钙网蛋白(CANX)和钙网蛋白(CALR)的表达量也上调了(约2倍)。综上所述,这些发现表明HCC细胞增强了初始糖基化和转移步骤,从而强化了N-糖基化的格局。
进一步支持这一趋势的是,参与N-糖链分支和延伸的多种N-乙酰氨基葡萄糖转移酶(GnT)显著上调。MGAT1(GnT-I)是一种重要的酶,催化高甘露糖聚糖转化为杂合或复杂结构,其表达上调约1.4倍,这与其已知的与HCC去分化和恶性转化的关联相符。更引人注目的是,负责添加β1,4-GlcNAc形成三分支和四分支聚糖的MGAT4A/B(GnT-IVa/IVb)表达上调约2倍,而生成β1,6-GlcNAc分支的关键酶MGAT5(GnT-V)表达显著上调超过3倍,β1,6-GlcNAc分支是肿瘤进展的标志。这与他们糖组学结果一致,即三分支和四分支聚糖表达上调(图 3i)。MGAT3(GnT-III)催化二分GlcNAc添加,并可以拮抗MGAT5介导的分支,从而发挥抗转移因子的作用,其表达也显著上调(约5倍)。这与糖组学结果也相符(图 3i)。此外,催化末端半乳糖基化的β -1,4-半乳糖基转移酶(B4GALT2/3/4/6)均显著过表达(约2倍)。值得注意的是,人肝脏中主要的β1,4-半乳糖基转移酶B4GALT1在TCGA-LIHC数据集中并不显著,但有报道称其在HCC组织中表达下调。因此,尽管观察到B4GALT2和B4GALT3表达上调,但它们更严格的底物特异性和狭窄的器官分布可能无法完全弥补B4GALT1活性的丧失,这与在糖组学数据中观察到的半乳糖基化总体下降相一致(图 3i)。
HCC组织中岩藻糖基化和唾液酸化均存在显著异常,而这两种修饰对于调节糖蛋白稳定性、受体信号传导和免疫逃逸至关重要。由FUT8催化的核心岩藻糖基化显著增加(约1.7倍)。此外,介导Lewis抗原岩藻糖基化的FUT3也高度上调(约4倍),提示肿瘤微环境向免疫抑制型转变。这与糖组学分析结果(图 3i)一致,即岩藻糖基化上调。在唾液酸化方面,多种α2,3和α2,6唾液酸转移酶(ST)均显著上调。催化α2,3-唾液酸化的ST3GAL2/3/4表达上调(1.7-3.3倍),而主要的α2,6-唾液酸转移酶ST6GAL1在HCC中仍保持高表达,尽管其表达量并未显著增加。值得注意的是,分别参与α2,6-和α2,3-唾液酸化的ST6GAL2和ST3GAL6均表达下调(分别下调约50%和1.6倍)。这些结果表明,HCC细胞优先通过ST6GAL1上调α2,6-唾液酸化,同时选择性地降低某些次要的唾液酸化途径,这与糖组学结果一致。在七个 GEO 数据集中进一步验证了糖基因表达模式(图 6c),表明在不同人群中,与疾病相关的N-糖基化失调具有高度保守性。
最后,他们进行了生存分析,以识别具有预后潜力的糖基化基因。在评估的307个糖基化基因中,分别有158个、141个、145个和109个与总生存期(OS)、疾病特异性生存期(DSS)、无进展生存期(PFI)和无病生存期(DFI)显著相关。值得注意的是,半乳糖基转移酶是关键的预后指标。例如,B4GALT2与总生存期显著相关(图 6d-e),而B4GALT3与疾病进展密切相关(图 6f-g)。此外,其他一些重要的糖基化基因,包括ALG3、DDOST、MAN1B1、MOGS和UGGT2,也表现出显著的预后价值。这些发现表明,糖基化可能在调节疾病进展和预后中发挥关键作用,并为未来的治疗干预提供潜在的靶点。
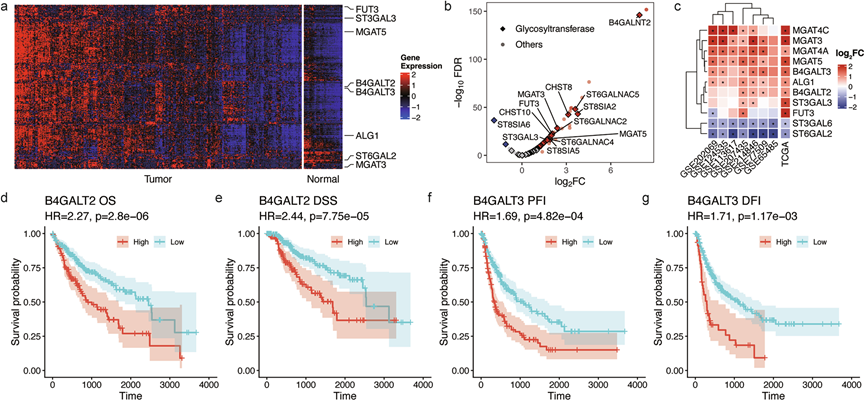
图6. 来自 TCGA 和 GEO 数据集的糖基因表达。
(a) TCGA-LIHC队列中参与N-糖基化通路(Reactome)的307个基因的基因表达情况。(b) TCGA-LIHC队列中307个糖基因的火山图。(c) TCGA-LIHC队列以及七个GEO数据集中的差异表达分析结果。(d-g) Kaplan-Meier生存曲线。
06
机器学习诊断模型的开发与验证
他们选取了26个缺失率低于1%的N-聚糖用于训练基于机器学习的诊断模型。其中,20个聚糖在四个组别间存在显著差异,14个在健康对照组(HC)和HCC之间存在差异,17个在CHB和HCC之间存在差异,13个在LC和HCC之间存在差异。所有26个检测可靠的聚糖均纳入模型,以捕捉潜在的非线性相互作用。GZ-I队列随机分为训练集(n = 526)和内部验证集(n = 218)。他们使用两个外部验证集( GZ-II队列n = 186;XZ队列n = 144)来评估模型的泛化能力(图 7a)。他们开发了三种模型,分别用于区分HCC 与 HC、HC 与 CHB 以及 HCC 与 LC 样本。这种方法支持预筛查策略,能够为已患有慢性肝病的患者提供个性化的 HCC 诊断(图 7b)。
利用最先进的AutoML技术,并参考训练集上的交叉验证性能,选择了最优算法和超参数配置。所有三个模型在内部验证集和两个外部验证集上均表现出较高的分类性能(图 7c-e)。在内部验证集上,模型1的ROC AUC为0.93,模型2的ROC AUC为0.90,模型3(HCC vs. LC)的ROC AUC为0.84。值得注意的是,尽管人口特征和医疗设施可能存在差异,但所有三个模型在外部验证队列(GZ-II 和 XZ)中均保持了一致的性能,仅略有下降(图 7c-e),这表明其具有强大的泛化能力和对分布变化的适应能力。
甲胎蛋白 (AFP) 是目前应用最广泛的HCC生物标志物,但其敏感性较低。相比之下,他们基于N-糖组的机器学习模型展现出更优异的诊断性能,能够检测出高达 80% 的 AFP 阴性 HCC 病例,凸显了其作为 HCC 诊断中一种稳健且灵敏的替代方法的潜力。与单独使用 AFP 相比,所有三个模型均表现出显著更优的性能。将糖组与 AFP 联合使用并未提高性能,表明N-糖组本身即可提供 AFP 所能提供的所有 HCC 诊断信息。这些结果突显了他们基于N-糖组的模型具有很高的诊断性能和稳健性,不仅优于目前的临床生物标志物 AFP,而且在两个独立的外部验证队列中也表现出一致的有效性。
随后,他们评估了在无预筛查的情况下,即区分HCC样本和所有非HCC样本时,N-糖组谱的诊断性能。模型4的性能与其他模型相当(图7f),优于AFP。为了进一步评估早期诊断的潜力,他们评估了这四个模型在不同TNM分期中的性能。所有四个模型在II期、III期和IV期均达到了0.80以上的ROC AUC,即使对于I期HCC患者,它们也保持了可接受的诊断效能,AUC值达到0.859(HCC vs HC)。这些结果表明,他们的模型在HCC的早期检测方面具有巨大的潜力。
他们还评估了模型 4 预测概率 (PP4) 在患者分层中的临床应用价值(图7g-l)。PP4 在所有组别中均表现出显著差异,包括三个对照组(健康对照组、慢性乙型肝炎组和肝硬化组;图 7g),表明其具有作为监测肝病进展的可靠标志物的潜力。此外,PP4 与 ALBI 分期(图 7h)和 Child-Pugh 分级(图 7j)均显著相关,并且在HCC样本中观察到一致的模式(图 7i-k)。这些发现突显了 PP4 反映肝功能状态的强大能力。此外,PP4 在 TNM 分期中也表现出显著差异,较高的 PP4 值对应于更晚期的癌症分期(图 7l),强调了其在癌症分期中的应用价值。
他们利用SHAP技术评估了四个诊断模型中特征的重要性(图 7m-p)。三种聚糖——H6N5F1S3、H5N4F1 和 H3N4F1——在所有模型中始终位列前三,且顺序保持不变。此外,另外三种聚糖——H5N2、H6N5S3 和 H5N4S1——始终位于第 4 至第 6 位之间,但顺序略有不同。置换特征重要性分析证实了这六种聚糖的重要性。此外,他们仅使用这六种最具信息量的聚糖训练机器学习模型,进一步验证了这些聚糖的重要性。模型在所有三个队列中均保持了几乎相同的性能,仅略有下降,但差异不显著。单独来看,这些聚糖的分类性能与模型相比并不理想,这表明它们的共同作用源于协同的非线性相互作用。这些聚糖来源于不同的糖基化位点:H5N2主要与IGHM N46连接,H5N4F1和H3N4F1主要与免疫球蛋白(例如IGHM、IGHG1、IGHA2)相关,而H6N5F1S3、H6N5S3和H5N4S1则具有不同的糖基化位点来源。
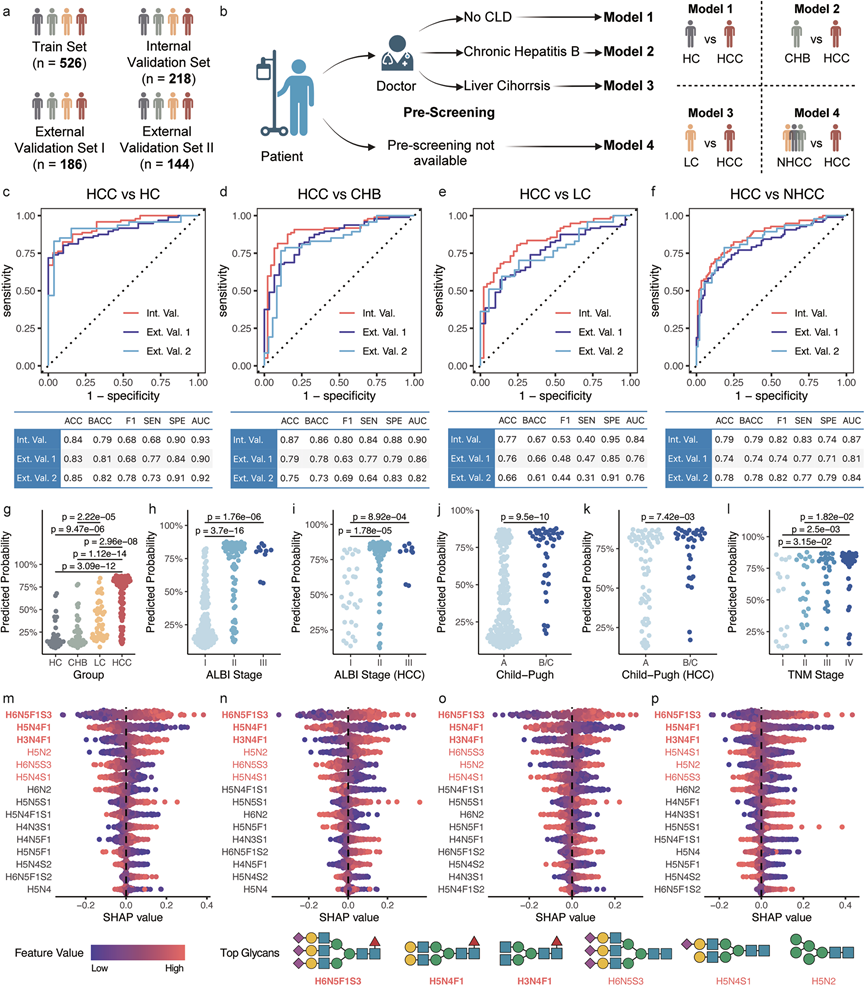
图7. 机器学习诊断模型。
(a) 用于机器学习训练和评估的数据集。(b) 预筛选建模策略。(c-f) 模型 1、模型 2、模型 3和模型 4在三个验证集上的受试者工作特征 (ROC) 曲线和详细分类指标。(g-l) 模型 4 (PP4) 在不同组别、ALBI 分期、Child-Pugh 分级和 TNM 分期中的预测概率分布。(m-p) 模型 1、模型 2、模型 3和模型 4的SHAP值瀑布图,并展示了前六种重要聚糖的可能结构。
+ + + + + + + + + + +
结 论
本研究利用高通量 N-聚糖释放、衍生化、富集和质谱分析流程,分析了来自多名健康个体、慢性乙型肝炎患者、肝硬化患者和 HCC 患者的血清N-糖组。HCC的进展以分支和岩藻糖基化显著增加、GlcNAc 水平升高和半乳糖基化水平降低为特征。基于这些聚糖特征构建的机器学习模型实现了较高的诊断准确率,并在两个外部队列中验证了其性能。整合糖蛋白组学分析进一步阐明了驱动这些聚糖变化的调控通路,突出了N-糖基化作为机制洞察和早期 HCC 检测的一个有希望的轴心。
+ + + + +



