

 English
English文献解读|EMBO Mol Med(11.1):早期妊娠血浆的蛋白质组分析揭示了先天性心脏病的新生物标志物
✦ +
+
论文ID
原名:Proteome profiling of early gestational plasma reveals novel biomarkers of congenital heart disease
译名:早期妊娠血浆的蛋白质组分析揭示了先天性心脏病的新生物标志物
期刊:EMBO Molecular Medicine
影响因子:11.1
发表时间:2023.10.16
DOI号:10.15252/emmm.202317745
背 景
先天性心脏病 (CHD) 的产前诊断主要依赖于孕中期进行的胎儿超声心动图检查,其敏感性因中心和医生而异,需要一种客观的早期诊断方法,并且开发CHD早期诊断的新方法对于出生缺陷的预防和治疗至关重要。目前在识别生物标志物方面取得的进展仍然不能满足对改进的生物标志物用于CHD早期诊断的迫切需求。
实验设计
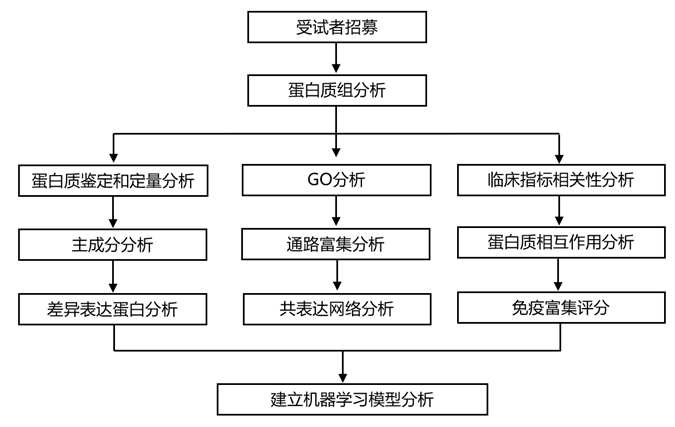
结 果
01

母体血浆的蛋白质组学表征
为了绘制先心病后代和健康后代在妊娠早期血浆蛋白质组的变化,他们分析了两个独立的病例对照组,总共招募了 206 名个体。其中包括复旦大学妇产科医院招募的第1组67例冠心病后代患者和71名对照者,以及中国福利会国际和平妇幼保健院招募的第2组37例病例和32名对照者,总计103 个对照和 104 个病例,最常见的表型是室间隔缺损(VSD)和 心房间隔缺损(ASD)(图1A)。基于数据独立采集(DIA)方法对所有样品进行蛋白质组学分析。他们对每个血浆样本平均 2220 个(第 1 组)和 1926 个(第 2 组)蛋白质进行了定量(图 1B)。在第 1 组和第 2 组中分别鉴定了 8624 个和 7049 个蛋白质(图 1C-D)。随着样本数量的增加,蛋白质数量逐渐趋于稳定,表明蛋白质检测的覆盖深度和稳定性良好。对 2 μl 血浆样本进行了深度蛋白质组覆盖(图 1E)。DIA获取的数据中,完整性为100%的蛋白质有351个,完整性为75%的蛋白质有1023个,完整性为50%的蛋白质有1604个(图1E)。在所有样本中,对照组和 CHD 组的定量蛋白质强度跨越了 8 个数量级,前 10 个高丰度蛋白质分别占数据集中所有血浆蛋白质丰度的 40% 和 39%(图 1F)。
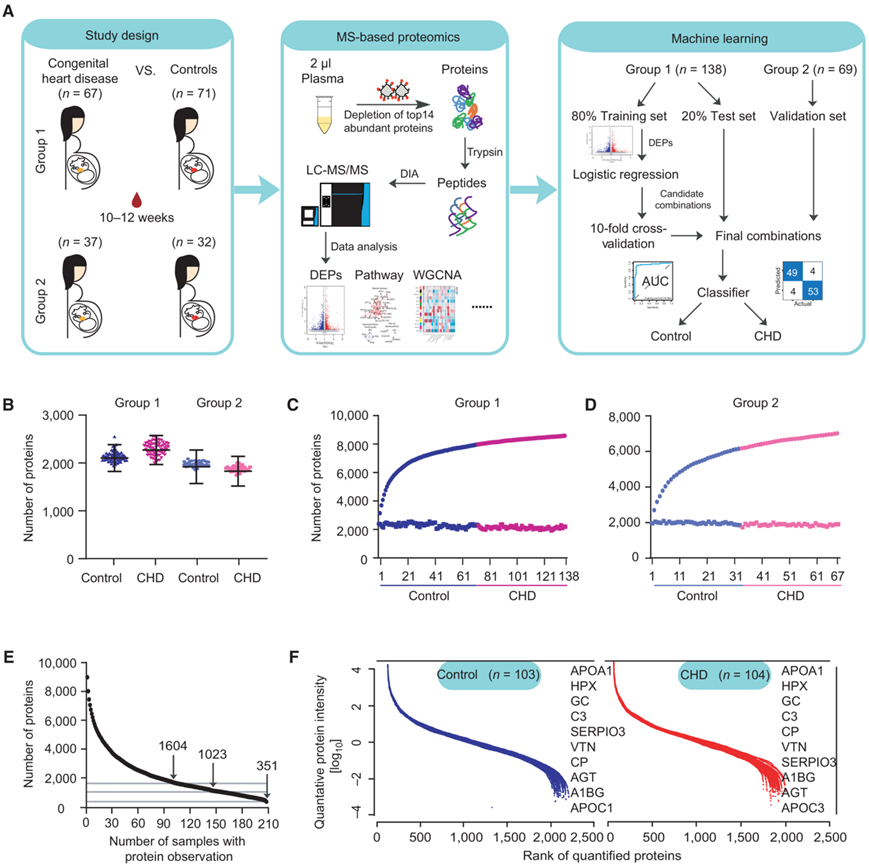
图1. 母体血浆的研究概述和蛋白质组学表征。
(A) 研究组概述和蛋白质组分析示意图。 (B) 对蛋白质进行定量。(C) 第 1 组中鉴定出的蛋白质的累积数量。(D) 第 2 组中鉴定出的蛋白质的累积数量。(E) 数据完整性曲线。(F) 绘制了 CHD 组(红色)和对照组(蓝色)的蛋白质丰度分布。
02
血浆中CHD相关蛋白质组变化的检测
主成分分析(PCA)显示两组病例和对照之间存在明显差异,表明在妊娠早期,患有CHD胎儿的孕妇表现出与携带健康胎儿的孕妇不同的血浆蛋白质组学特征(图2A-C)。此外,他们还确定了两组中与 CHD 相关的个体分子特征。第 1 组显示对照组和 CHD 组之间存在 397 个差异表达蛋白 (DEP)。其中, 在 CHD 组中检测到 184 个显著上调的蛋白和 213 个下调的蛋白(图2B)。在第 2 组中,在对照组和 CHD 组之间确定了 225 个 DEP。其中,CHD 组中有 80 个蛋白质显著上调,145 个蛋白质显著下调(图2D)。这些DEP包括一些先前鉴定的血浆CHD标志物,例如神经毡蛋白-2、ATP-柠檬酸合酶(ACLY)、蛋白S100-A7(S100A7)、肌球蛋白调节轻链多肽9(MYL9)、葡萄糖-6-磷酸1-脱氢酶(G6PD)、丝氨酸羟甲基转移酶 (SHMT1)、辅肌动蛋白样蛋白 (COTL1) 和纤溶酶原激活剂抑制剂 1 (SERPINE1)。
为了进一步分析母体血浆中改变的蛋白质的概况,他们使用GO分析注释了两组中显著的 DEP,并确定了受胎儿 CHD 影响的生物过程。在两组中,CHD组中显著上调的264个蛋白主要富集在氨基酸代谢、细胞外基质(ECM)受体、肌动蛋白骨架调节、Ras-MAPK信号通路和PI3K-Akt信号通路中。相反,358 种显著下调的蛋白质与碳水化合物代谢、心肌收缩和心肌病密切相关(图 2E)。此外,为了了解各种上调和下调蛋白质的分子通路关系,对改变的蛋白质进行了蛋白质-蛋白质相互作用(PPI)网络分析,揭示了每个通路中的关键分子(图2F)。这些结果表明,患有CHD胎儿的孕妇的母体血浆表达了大量与胚胎器官发育相关的蛋白质,与健康胎儿的蛋白质显著不同,这些显著改变的蛋白质可能作为疾病的生物标志物。
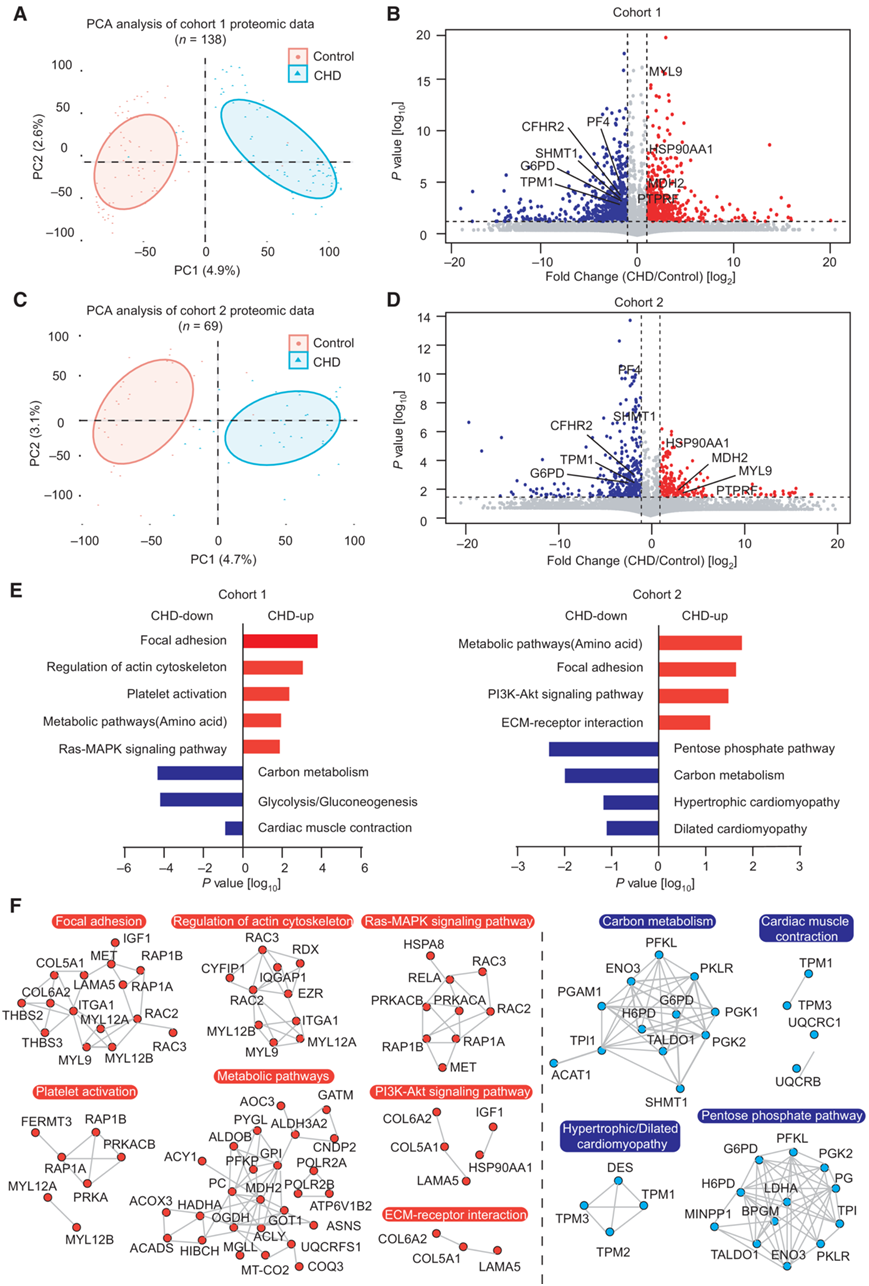
图2. 两组 CHD 与对照血浆蛋白质组的差异。
(A) 对第 1 组血浆样本中的蛋白质进行主成分分析 (PCA)。 (B) CHD/对照样本的差异倍数与第 1 组的统计显著性之间的关系。(C) 第 2 组血浆蛋白的 PCA。(D) CHD/对照样本的差异倍数与第 2 组的统计显著性之间的关系。 (E) 上调或下调蛋白质。 (F) 两组富集通路的蛋白质相互作用分析。
03
两组CHD相关蛋白的变化分析
八种已知的CHD相关蛋白的表达水平,包括热休克蛋白HSP 90α(HSP90AA1)、苹果酸脱氢酶(MDH2)、ACLY、N-乙基马来酰亚胺敏感因子(NSF)、α-原肌球蛋白基因(TPM)、SERPINE1、和补体因子 H 相关 2 (CFHR2)在两组中均发生一致改变。CHD组HSP90AA1、MDH2、MYL9、ACLY蛋白表达水平高于对照组。相反,CHD组中NSF、TPM1、SERPINE1和CFHR2的蛋白表达水平低于对照组(图 3A)。这些结果表明母体血浆表达的蛋白质与心脏发育相关。此外,CHD 和对照血浆之间 74 种蛋白质水平的变化在第1组和第2组之间是一致的。两组中总共有 25 种蛋白质显著上调,49 种蛋白质显著下调(图 3B)。他们进一步分析了这74个DEP,发现25个上调的蛋白主要涉及代谢、先天免疫反应和细胞周期通路,而49个下调的蛋白主要涉及糖代谢、脂质代谢和血管相互作用等过程。这些通路可能对于胎儿心脏发育至关重要(图3C-D)。

图3. 两组血浆蛋白质组变化。
(A) 心脏病相关蛋白的表达水平。(B) 上调和下调蛋白质的维恩图。 (C) 两组中已鉴定蛋白质的表达水平和通路富集。 (D) 两组差异表达蛋白的通路模式。
04
CHD蛋白共表达网络的构建与验证
了确定 CHD 病理学的潜在驱动因素,他们在后续分析中纳入了缺失值低于 30% 的蛋白质,并使用加权基因共表达网络分析 (WGCNA) 选择了大约 2,280 个蛋白质来生成蛋白质共表达网络。共表达网络由 10 个蛋白质模块(M1-M10)组成,其大小范围为 20 至 492 个蛋白质(图4A)。随后,对12种临床病理表型进行层次聚类分析,分为以下三个表型聚类:聚类1,包括法洛四联症(TOF)、主动脉瓣狭窄(AS)、持续性动脉干(PTA)、大动脉转位(TGA)和右心室流出道梗阻(RVOTO);第 2 组,包括三尖瓣反流 (TR) 和ASD;第 3 组,包括肺动脉狭窄 (PS)、VSD、持续性左上腔静脉 (PLSVC)、左心室流出道梗阻 (LVOTO) 和房室间隔缺损 (AVSD)。
他们观察到与临床表型聚类显著相关的六个模块。聚类1 与蛋白质模块 4 和 8 显著相关,并且富含碳水化合物代谢、谷胱甘肽代谢和免疫反应。聚类2 与蛋白质模块 9 和 10 显著相关,并且在 ECM 受体反应、蛋白质转运和信号转导方面富集。聚类3 与蛋白质模块 2 和 3 显著相关,并且主要富集于心肌生长、发育的调节和肌动蛋白细胞骨架的调节(图 4B)。为了进一步研究不同簇中影响疾病发生的潜在因素,他们分析了 PPI 网络的通路(图 4B)。数据揭示了每个通路中的关键分子,例如淀粉酶 α 2A (AMY2A)、免疫球蛋白 lambda 样多肽 5 (IGLL5)、MYL9、整合素亚基 α 1 (ITGA1)、RAB6A、RAS 癌基因家族成员 (RAB6A) 和连环蛋白beta 1 (CTNNB1)(图 4C)。这些核心基因可以将 CHD 与对照组区分开来。
此外,他们研究了 10 个蛋白质模块和 18 个临床指标之间的关系,只有 3 个模块(M2、M3 和 M6)与 CHD 病理表现出很强的相关性。聚类 3(M2 和 M3)与血脂呈正相关,与甲状腺激素呈正相关。这些结果进一步表明血脂和甲状腺激素水平升高可能是冠心病的危险因素。此外,M6水平与甲状腺素激素水平呈负相关(图 4D)。此外,他们比较了对照组和不同CHD组的妊娠早期妇女血浆中七种脂质的浓度,发现CHD组中游离脂肪酸的水平显著下调,而其他六种脂质,包括低密度脂蛋白(LDL)、甘油三酯、高密度脂蛋白、总胆固醇(TC)、载脂蛋白A(APOA)和载脂蛋白B(APOB),在CHD组中表达上调(图 4E)。这些结果与之前的研究结果一致,即脂质是冠心病的主要危险因素,表明血脂波动可能与冠心病的发生有关。他们进一步检查了 CHD 和对照样本之间的 DEP。在模块2的这26个蛋白质中,有两个蛋白质与血脂水平呈正相关(图 4F)。
为了研究冠心病发生后免疫微环境的变化,他们使用xCell基于蛋白质组生成细胞型免疫富集评分。在这里,他们鉴定了21种与免疫(CD4+ T细胞和NK细胞)或基质(脂肪细胞和内皮细胞)特征相关的不同细胞类型,并通过存在或不存在特定细胞类型来区分每个样本(图4G)。对照组内皮细胞、肌细胞和周细胞富集,而冠心病组CD4+ T细胞、脂肪细胞和前脂肪细胞富集(图4G)。具体来说,CD4+ T细胞和前脂肪细胞在聚类3富集,脂肪细胞和前脂肪细胞在聚类2富集(图4G-H)。这些结果表明,冠心病的发生伴随着血脂、脂肪细胞和CD4+ T细胞的增加,内皮细胞、肌细胞和周细胞的减少,这些可能参与了冠心病的发病机制(图4I)。血脂升高通过抑制心肌细胞增殖和迁移、阻碍血管生成和激活CD4+ T细胞诱发冠心病。活化的CD4+ T细胞可释放促炎细胞因子,激活巨噬细胞和血管细胞,引起急性炎症。它们还可以引起慢性炎症状态,这可能进一步损害心脏发育(图4I)。
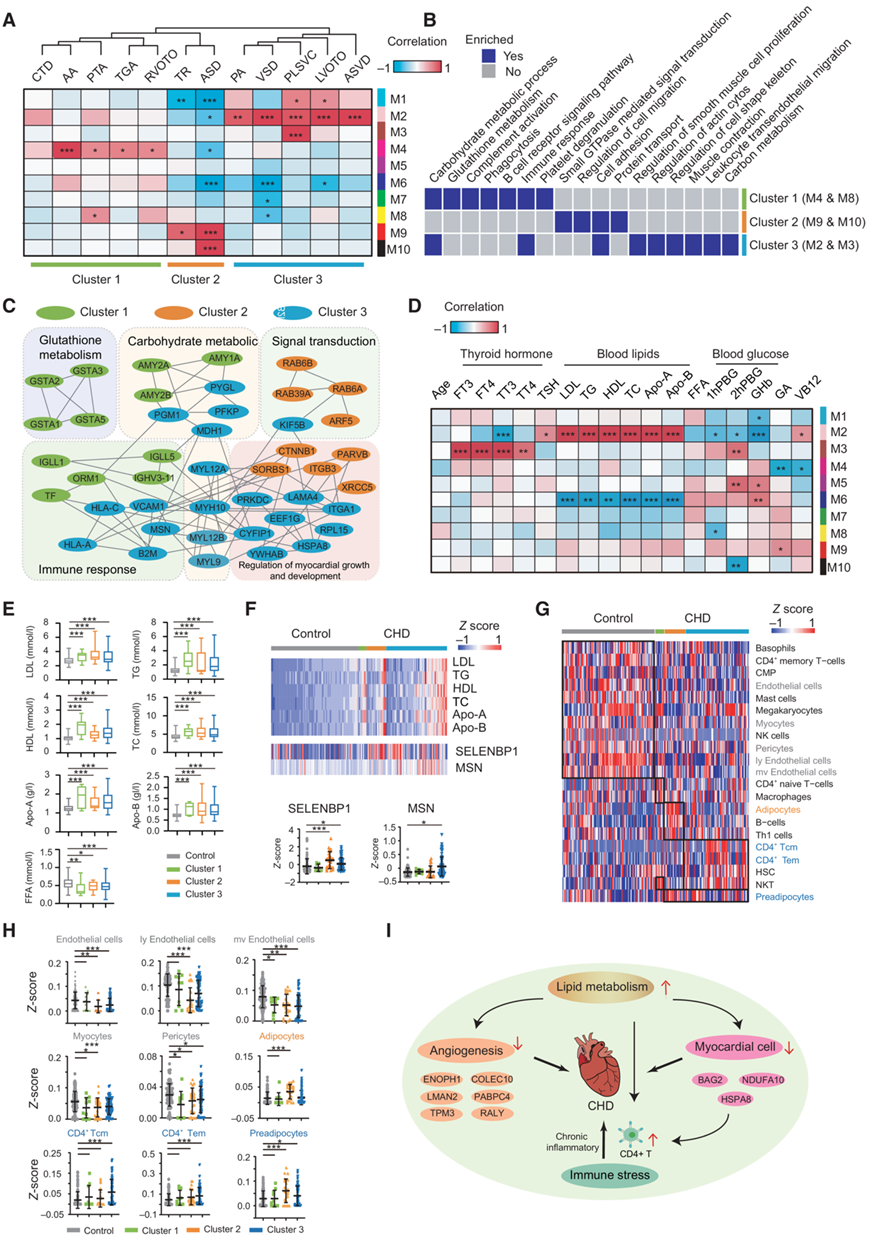
图4. CHD血浆蛋白质组与临床表型及指标的关系。
(A) 对207个血浆样本的加权基因共表达网络分析(WGCNA)显示,根据模块蛋白之间的相关性,CHD的12个病理特征可以整合成三个聚类。(B)GO分析。(C) 三个主要病理特征的PPI网络分析。(D) 分析不同CHD蛋白网络的变化及其与临床指标的相关性。(E) 对照组和先心病患者的血脂表达水平。(F) 蛋白质表达与临床指标(血脂)的相关性。 (G) 对照组和先心病中特定免疫细胞聚类类型的热图。(H) 散点图显示了对照组和 CHD 组中特定细胞类型的 xCell 分数。 (I) 血脂与冠心病的潜在发病机制。
05
基于机器学习识别冠心病的生物标志物组合的鉴定
根据第 1 组的血浆蛋白质组学数据,他们使用机器学习方法来识别潜在的生物标志物组合,以识别妊娠早期孕妇中患有先心病的胎儿。为了优化训练模型的参数并评估模型性能,他们进行了 10 倍交叉验证。机器学习模型基于第1组80%的蛋白质组学数据建立,选择包含以下9种蛋白质的生物标志物组合:钙蛋白酶-5(CAPN5)、烯醇化酶磷酸酶E1(ENOPH1)、组蛋白H2A 1-C型(H2AC6)、HSP90AA1、输入亚基 beta-1 (KPNB1)、MDH2、MYL9、radixin (RDX) 和 SAMHD1。该模型在训练集中的曲线下面积 (AUC) 为 0.964(图 5A)。第 1 组的剩余数据用于测试数据集,其 AUC 值为 0.989(图 5D)。这些结果表明,这种生物标志物组合对于基于母体血浆样本诊断 CHD 具有临床意义。为了进一步验证该组合的性能,他们从第2组收集了69份血浆样本进行组间验证(32例对照和37例CHD病例),AUC值为0.963(图 5G)。此外,评估机器学习策略的可靠性,这些生物标志物组合的混淆矩阵和 PCA 结果显示,对照组和 CHD 组的分类准确性相对较高(图 5B-I)。

图5. 利用机器学习开发生物标志物组合来预测 CHD 。
(A-C) 第 1 组训练数据集的受试者工作特征 (ROC) 曲线,训练数据集中组合生物标志物的混淆矩阵,以及用于预测 CHD 和对照结果的 PCA 图。 (D-F)第 1 组测试数据集的 ROC 曲线,测试数据集中组合生物标志物的混淆矩阵,以及用于预测 CHD 和对照结果的 PCA 图。(G-I) 第 2 组中外部验证集的 ROC 曲线,外部验证集中组合生物标志物的混淆矩阵,以及用于预测 CHD 和对照结果的 PCA 图。
+ + + + + + + + + + +
结 论
本项研究招募了 103 名具有健康后代的孕妇和 104 名患有 CHD 后代的病例,包括 VSD (42/104)、ASD (20/104) 和其他 CHD 表型,在妊娠早期收集血浆并进行蛋白质组分析。PCA揭示了对照组和 CHD 之间存在显著差异,在显著改变的蛋白质中,CHD中25个上调的蛋白质在氨基酸代谢、细胞外基质受体和肌动蛋白骨架调节方面富集,而49个下调的蛋白质在碳水化合物代谢、心肌收缩和心肌病方面富集。机器学习模型的曲线下面积达到 0.964,识别 CHD 的准确率很高。这项研究为更好地识别冠心病的病因提供了非常有价值的蛋白质组学资源,并为冠心病的早期识别、促进早期干预和更好的预后开发了可靠的客观方法。
+ + + + +



